
本文介绍Flink SQL用SPL完成行过滤与列裁剪的操作步骤。
背景
在阿里云Flink配置SLS作为源表时,默认会消费SLS的Logstore数据进行动态表的构建,在消费的过程中,可以指定起始时间点,其消费的数据是指定时间点以后的全量数据。这样做有两个问题:
Connector 从源头拉取了过多不必要的数据行或者数据列,造成了网络的开销。
这些不必要的数据需要在Flink中进行过滤投影计算,这些清洗工作并不是数据分析的关注重点,造成了计算浪费。
为此,SLS SPL为Flink SLS Connector提供了过滤下推和投影下推的能力。通过配置SLS Connector的query语句或参数,可以实现过滤条件和投影字段的下推,避免全量数据传输和计算,提升效率。
方案原理
未配置SPL语句时:Flink会拉取SLS的全量日志数据(包含所有列、所有行)进行计算,如图所示。

配置SPL语句时:当SPL语句包含行过滤或列裁剪操作时,Flink拉取的数据是经过这些操作处理后的部分数据,用于后续计算,如图所示。

准备工作
已开通日志服务,已创建Project和Logstore。
本文Logstore数据使用SLS的SLB七层日志模拟接入方式产生模拟数据,其中包含10多个字段。模拟接入会持续产生随机的日志数据,日志内容示例如下:
{ "__source__": "127.0.0.1", "__tag__:__receive_time__": "1706531737", "__time__": "1706531727", "__topic__": "slb_layer7", "body_bytes_sent": "3577", "client_ip": "114.137.XXX.XXX", "host": "www.pi.mock.com", "http_host": "www.cwj.mock.com", "http_user_agent": "Mozilla/5.0 (Windows NT 6.2; rv:22.0) Gecko/20130405 Firefox/23.0", "request_length": "1662", "request_method": "GET", "request_time": "31", "request_uri": "/request/path-0/file-3", "scheme": "https", "slbid": "slb-02", "status": "200", "upstream_addr": "42.63.XXX.XXX", "upstream_response_time": "32", "upstream_status": "200", "vip_addr": "223.18.XX.XXX" }Logstore中slbid字段有三种值,对15分钟的日志数据进行slbid统计,可以发现
slb-01与slb-02数量相当。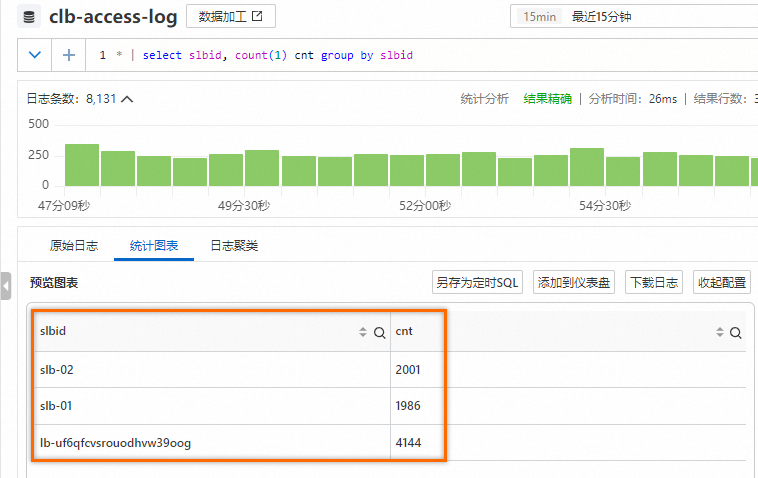
操作步骤
行过滤:SLS SPL为Flink SLS Connector提供了一种支持过滤下推的能力,通过配置SLS Connector的query语句中的过滤条件,即可实现过滤条件下推。避免全量数据传输和全量数据过滤计算。
列过滤:SLS SPL为Flink SLS Connector提供了一种支持投影下推的能力,通过配置SLS Connector的query参数,即可实现投影字段下推。避免全量数据传输和全量数据过滤计算。
行过滤场景
步骤一:创建SQL作业
登录实时计算控制台,单击目标工作空间。
在左侧导航栏,选择。
单击新建,在新建作业草稿对话框,选择,单击下一步。
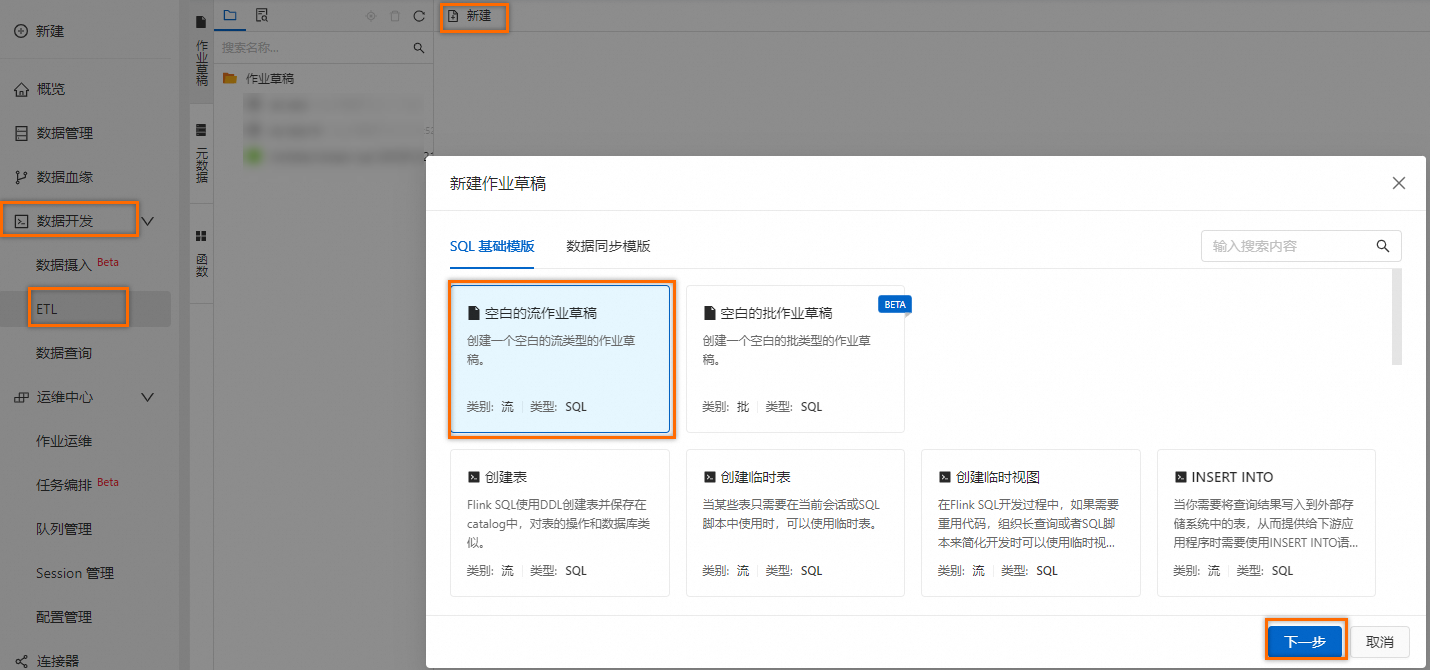
拷贝如下创建临时表的SQL到SQL编辑区域。
CREATE TEMPORARY TABLE sls_input( request_uri STRING, scheme STRING, slbid STRING, status STRING, `__topic__` STRING METADATA VIRTUAL, `__source__` STRING METADATA VIRTUAL, `__timestamp__` STRING METADATA VIRTUAL, __tag__ MAP<VARCHAR, VARCHAR> METADATA VIRTUAL, proctime as PROCTIME() ) WITH ( 'connector' = 'sls', 'endpoint' ='cn-hangzhou-intranet.log.aliyuncs.com', 'accessId' = 'yourAccessKeyID', 'accessKey' = 'yourAccessKeySecret', 'starttime' = '2025-02-19 00:00:00', 'project' ='test-project', 'logstore' ='clb-access-log', 'query' = '* | where slbid = ''slb-01''' );SQL中的参数说明如下:
参数名
参数含义
示例值
connector
连接器。更多信息,请参见支持的连接器。
sls
endpoint
日志服务的私网域名,获取方式请参见服务接入点。
cn-hangzhou-intranet.log.aliyuncs.com
accessId
用户身份识别ID,获取方式,请参见创建AccessKey。
LTAI****************
accessKey
用于验证您拥有该AccessKey ID的密码。获取方式,请参见创建AccessKey。
yourAccessKeySecret
starttime
指定查询日志的起始时间点。
2025-02-19 00:00:00
project
日志服务的Project名。
test-project
logstore
日志服务的Logstore名。
clb-access-log
query
填写SLS的SPL语句,注意在阿里云Flink的SQL作业开发中,字符串需要使用英文单引号进行转义。
* | where slbid = ''slb-01''
鼠标选中SQL,鼠标右击,单击运行,连接SLS。
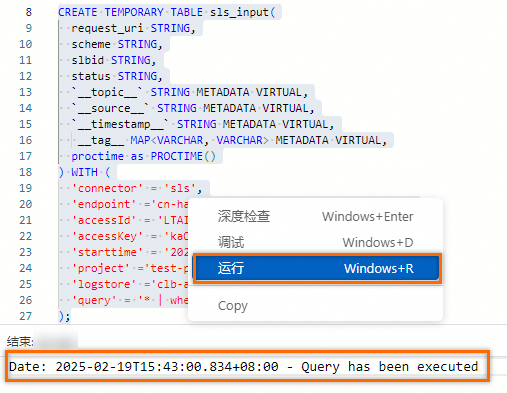
步骤二:连续查询及效果
在作业中输入如下分析语句,按照slbid进行聚合查询。
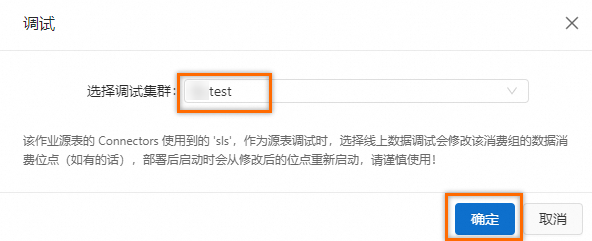
SELECT slbid, count(1) as slb_cnt FROM sls_input GROUP BY slbid;单击右上角调试按钮,在调试弹框,单击选择调试集群下拉框中的创建新的集群,参考下图,创建新的调试集群。
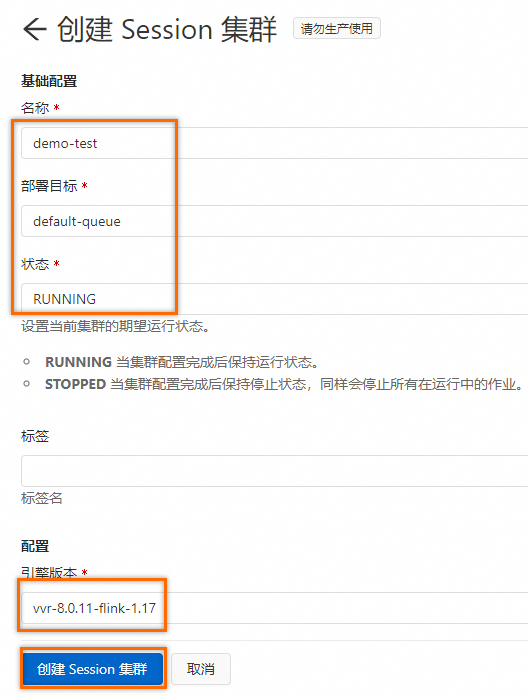
在调试弹框选择创建好的调试集群,然后单击确定。
在结果区域,可以看到结果中slbid的字段值,始终是
slb-01。可以看出设置了SPL语句后,sls_input仅包含slbid='slb-01'的数据,其他不符合条件的数据被过滤掉了。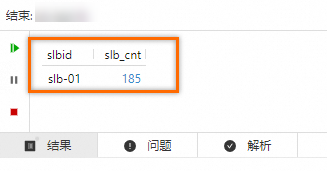
列裁剪场景
步骤一:创建SQL作业
登录实时计算控制台,单击目标工作空间。
在左侧导航栏,选择。
单击新建,在新建作业草稿对话框,选择,单击下一步。
拷贝如下创建临时表的SQL到SQL编辑区域。与行过滤场景不同的是,这里query参数配置进行了修改,在过滤的基础上增加了投影语句,使用
|符号(类似Unix管道)将不同指令进行分割,上一条指令的输出作为下一条指令的输入,最后指令的输出表示整个管道的输出。实现从SLS服务端仅拉取特定字段的内容。CREATE TEMPORARY TABLE sls_input_project( request_uri STRING, scheme STRING, slbid STRING, status STRING, `__topic__` STRING METADATA VIRTUAL, `__source__` STRING METADATA VIRTUAL, `__timestamp__` STRING METADATA VIRTUAL, __tag__ MAP<VARCHAR, VARCHAR> METADATA VIRTUAL, proctime as PROCTIME() ) WITH ( 'connector' = 'sls', 'endpoint' ='cn-hangzhou-intranet.log.aliyuncs.com', 'accessId' = 'yourAccessKeyID', 'accessKey' = 'yourAccessKeySecret', 'starttime' = '2025-02-19 00:00:00', 'project' ='test-project', 'logstore' ='clb-access-log', 'query' = '* | where slbid = ''slb-01'' | project request_uri, scheme, slbid, status, __topic__, __source__, "__tag__:__receive_time__"' );SQL中的参数说明如下:
参数名
参数含义
示例值
connector
连接器。更多信息,请参见支持的连接器。
sls
endpoint
日志服务的私网域名,获取方式请参见服务接入点。
cn-hangzhou-intranet.log.aliyuncs.com
accessId
用户身份识别ID,获取方式,请参见创建AccessKey。
LTAI****************
accessKey
用于验证您拥有该AccessKey ID的密码。获取方式,请参见创建AccessKey。
yourAccessKeySecret
starttime
指定查询日志的起始时间点。
2025-02-19 00:00:00
project
日志服务的Project名。
test-project
logstore
日志服务的Logstore名。
clb-access-log
query
填写SLS的SPL语句,注意在阿里云Flink的SQL作业开发中,字符串需要使用英文单引号进行转义。
* | where slbid = ''slb-01''
鼠标选中SQL,鼠标右击,单击运行,连接SLS。
步骤二:连续查询及效果
在作业中输入如下分析语句,按照slbid进行聚合查询。
SELECT slbid, count(1) as slb_cnt FROM sls_input_project GROUP BY slbid;单击右上角调试按钮,在调试弹框,单击选择调试集群下拉框中的创建新的集群,参考下图,创建新的调试集群。
在调试弹框选择创建好的调试集群,然后单击确定。
在结果区域,可以看到结果与行过滤场景结果类似。
说明注意:这里与行过滤不同的是,行过滤场景会返回全量的字段,而当前的语句令SLS Connector只返回特定的字段,再次减少了数据的网络传输。