
本文介绍查询与分析日志的常见报错及对应的解决方法。
日志服务控制台查询分析后报错
如果是查询分析语句相关的问题可以借助Copilot智能辅助工具帮助排查,也可以使用SQL优化进行分析,具体请参考Copilot:AI辅助SQL语句自动生成。
logstore * does not exist
错误描述
您当前查询的Logstore在当前地域当前Project下不存在。
报错原因
该Logstore已被删除。
该Logstore本身就不存在,可能在其他Project下。
该Logstore本身就不存在,可能在其他Region下。
解决方法
检查您需要查询的目标Logstore,并确定其是否存在。
logstore without index config
错误描述
您当前正在使用SQL语法,而Logstore并没有配置索引,使用SQL必须至少配置任一索引。
报错原因
您当前查询的目标Logstore没有配置索引。
解决方法
检查您需要查询的目标Logstore,并确定已开启索引配置(至少一列)。
Too many queued queries
错误描述
您当前查询的Logstore中索引字段别名发生冲突,SQL无法确定您想要分析的具体列。
原理解释
SLS SQL并发配额是用户Project级别隔离,同一个Project中的多个SQL请求提交到SLS服务端,当SQL正在执行中,将占用一个SQL并发配额;当SQL执行完成,将归还本次分配的SQL并发配额。 用户一个Project的SQL并发配额,执行普通SQL模式时为15,执行增强SQL模式时为150。
报错原因
您的并发请求数过高。
您单次请求SQL的延时较高。
您的业务代码中SQL请求异常重试逻辑导致的大量循环重试。
解决方法
降低请求量。
优化SQL,减少单次SQL的执行延时。
重试逻辑增加随机等待时间,避免无效重复的循环重试,导致额外并发请求压力的增加。
duplicate column conflicts
错误描述
您当前查询的Logstore中索引字段别名发生冲突,SQL无法确定您想要分析的具体列。
报错原因
该Logstore中某列名与某列的别名完全一样。
解决办法
检查您需要查询的目标Logstore的索引列字段,确保命名没有冲突。
denied by sts or ram, action:*
错误描述
您当前查询的Logstore在您当前身份下没有权限。
报错原因
该Logstore未授权给您当前身份。
解决方法
检查RAM权限,并授权该Logstore读权限给您当前身份,授权资源描述:
action: log:GetLogStoreLogs, resource: acs:log:<region>:<uid>:project/<project>/logstore/<logstore>
you are using nested sql, please specify FROM LOGSTORE in the innermost sql
错误描述
您正在SQL中使用嵌套子查询,请在最内层的子查询中指定表名。
报错原因
SLS为了简化用户查询,在进行单表查询时,默认指定当前所在Logstore为FROM所在表。假设您当前Logstore名为test,那么,以下3个查询语句是同义的:
语句1:您可以不指定FROM子句。
语句2:您可以使用FROM log,这将指定当前所在Logstore。
语句3:您可以明确指定您查询的表为Logstore为test。
但当您进行包含子查询的复杂查询时,SLS无法为您推断各子查询中目标表,所以您必须在子查询中手动指定FROM子句。
解决方法
如果您想查询当前Logstore,您可以直接使用"FROM log"常量字符串指定From表为当前Logstore。
当然您也可以明确指定您要查询的目标Logstore名字。
IN value and list items must be the same type: varchar
错误描述
SQL语句中存在语法错误,IN子句中的值和列表项必须是同一数据类型:varchar。
报错原因
在使用IN操作符进行查询时,提供的值和列表项数据类型不一致,例如值为varchar类型,列表项为整数类型。
解决方法
确保IN操作符中提供的值和列表项数据类型一致。可以使用CAST或CONVERT函数将数据类型进行转换,或者将值和列表项都转换为相同的数据类型后再进行查询。另外,建议在写入日志时,对应的列字段应该使用相同的数据类型,以避免类似的错误。
Unexpected parameters (bigint) for function url_decode. Expected: url_decode(varchar(x))
错误描述
SQL语句中存在语法错误,使用SQL函数时,输入的参数类型不正确。
报错原因
该函数需要接收一个字符串类型的参数,但是输入的参数类型为bigint。
这类错误可能出现在不同的函数中,不一定是url_decode,也有可能是regexp_like,但错误原因一样:使用SQL函数时,输入的参数类型不正确。
解决方法
将输入的参数转换为字符串类型后再传递给url_decode函数。可以使用CAST或CONVERT函数将bigint类型的参数转换为字符串类型的参数,或者直接在调用该函数时使用引号将参数括起来,将其转换为字符串类型。例如:
SELECT url_decode(CAST(bigint_param AS varchar(20))) -- 使用CAST函数将bigint类型参数转换为字符串类型SELECT url_decode('123456789') -- 若参数是字面量,可以直接将参数括起来,将其转换为
target of repeat operator is not specified
错误描述
重复操作符的目标未指定。
报错原因
这可能是正则表达式中的错误,提示重复操作符的目标未指定。重复操作符“()”用于匹配前面的字符或组的零个或多个出现,但它需要一个目标来应用重复。例如,"(a) *"表示零个或多个出现的字母"a"。如果没有指定目标,例如在"() *"中,正则表达式引擎将不知道要如何应用重复操作符,从而会抛出该错误。
解决方法
您需要检查正则表达式中的重复操作符“()”是否有正确的目标,并进行相应修正。
NULL values are not allowed on the probe side of SemiJoin operator. See the query plan for details.
错误描述
NULL值不允许出现在半连接(SemiJoin)的探测端。
报错原因
在半连接中,探测端不能出现非NULL值,否则半连接无法正确执行。可能是查询运行时的probe表中某行记录或子查询返回了NULL值。
解决方法
请检查查询计划以确定哪个表返回了NULL值。如果涉及到子查询,请确保其子查询返回的结果集不包含 NULL 值。如果是外部表中的NULL值导致了问题,可以考虑使用 INNER JOIN 替代半连接,或使用 COALESCE 或 ISNULL函数来处理NULL值。
Array subscript out of bounds
错误描述
数组下标越界。
报错原因
您使用数组时,正在尝试访问了一个超出数组范围的索引位置。例如,访问负数索引、超出数组长度的索引等。这可能是因为SQL中存在错误的逻辑或者数据输入错误。
解决方法
SQL中数组索引位置从1开始计起,请检查SQL中数组的有效长度,然后检查数组索引位置的引用情况,并确保数组的下标没有超出范围。
Expression "*" is not of type ROW
错误描述
表达式'fields'不是ROW类型。
报错原因
在使用ROW类型时,表达式“fields”不符合ROW类型的要求。可能是因为在使用ROW函数时,参数不符合要求。
解决方法
请检查ROW函数的参数是否正确,并且参数中所有的字段是否存在且符合要求。如果参数正确,但结果仍然不是ROW类型,可以尝试使用CAST函数将其转换为ROW类型。
Key-value delimiter must appear exactly once in each entry. Bad input: '*'
错误描述
每个条目中的键值分隔符必须出现一次。
报错原因
在输入中的某个键值对中,分隔符出现了不止一次,或者没有出现,导致系统无法解析该键值对。
解决方法
请检查输入中的键值对格式是否正确,确保每个键值对中只有一个分隔符,并且分隔符两侧都有正确的键和值。
Pattern has # groups. Cannot access group
错误描述
正则匹配无法访问指定组。
报错原因
正则匹配到0个组,无法访问第1个组。 有可能在正则表达式中使用了分组语法,但是没有定义任何分组。在此情况下,无法访问分组,因为分组根本不存在。
解决方法
检查正则表达式中的分组语法,并确保至少有一个分组定义在模式中。可以使用圆括号 () 来定义分组。例如,要匹配一个字符串中的电子邮件地址,并将用户名和域名分别作为分组,请使用以下正则表达式:(w+)@(w+.w+)。在这个例子中,有两个分组,因此可以用 group(1) 和 group(2) 来访问分组的值。如果不需要分组,可以使用非捕获分组,例如:(?:w+)@(?:w+.w+)。如果问题依然存在,可以使用在线正则检查器进行在线调试,待验证无误后再填充到SQL中。
ts_compare must gropu by timestamp,your grouping by type is :bigint
错误描述
ts_compare函数必须按timestamp类型分组。
报错原因
您在SQL中使用ts_compare函数时,group by的列,可能是非timestamp类型的数值型或其他类型。
解决方法
请确保ts_compare函数对应的group by列类型使用正确的timestamp类型,您可以使用from_unixtime函数等函数将整型时间戳转换成timestamp类型。
time # is out of specified time range
错误描述
时间戳超出了指定的时间范围。
报错原因
在SQL语句中使用了超出指定时间范围的时间戳,可能是由于数据录入错误或者数据类型不匹配导致的。
解决方法
检查时间戳是否正确,如果是由于数据类型不匹配导致的,可以尝试使用相关的数据类型转换函数将时间戳转换为正确的数据类型。
ROW comparison not supported for fields with null elements
错误描述
ROW比较不支持带有NULL值的字段。
报错原因
在SQL语句中使用了包含NULL值元素的ROW类型比较操作,例如使用
=或!=运算符进行比较。解决方法
在行比较之前,需要先对包含NULL元素的ROW进行处理。可以使用类似IS NULL或者IS NOT NULL的操作符将NULL值筛选出来,或者使用COALESCE函数对NULL值进行处理。另外,也可以在日志数据写入和处理过程时,中早对包含NULL元素的行进行处理,避免出现以上错误。
The specified key does not exist.
错误描述
这通常发生在您使用OSS做外表关联查询时,访问OSS bucket失败:指定Key不存在。
报错原因
您正在访问的OSS bucket中不存在指定的对象,可能已被删除或者从未存在。这有可能是您指定了错误的OSS bucket端点,也可能是您指定了错误的对象Key。
解决方法
检查OSS bucket和待访问对象Key名称,确保无误。
前往OSS确认指定对象Key是否存在于指定的OSS bucket中。
reading data with pagination only allow reading max
错误描述
分页最大行数不能超过1,000,000。
报错原因
SLS SQL限制最大输出行数为1,000,000,您正在进行的分页读取请求超过了最大行数限制。
解决方法
通过LIMIT子句,限制分页读取最大行数不超过1,000,000。
通过缩小查询范围,限制分页读取最大行数不超过1,000,000。
利用Scheduled SQL服务,分窗口定期进行SQL汇聚分析,然后再对汇聚结果进行二次聚合。
Could not choose a best candidate operator. Explicit type casts must be added.
错误描述
无法选择最佳的候选操作符,必须添加显式类型转换。
报错原因
这通常是因为您正在尝试在不同类型变量之间执行算术或比较操作,而系统无法自动识别应该使用哪种类型的操作符。
解决方法
您需要添加显式的类型转换来告诉系统应该使用哪种类型的操作符。
例如,如果您正在尝试将一个字符串类型的变量和一个整数类型的变量相加,您可以使用CAST函数来将字符串类型的变量转换为整数类型,然后再执行加法操作。示例代码如下:
SELECT CAST('10' AS INTEGER) + 5;在这里,我们使用CAST函数将字符串类型的变量'10'转换为整数类型,然后将其与整数类型的变量5相加。这样可以避免出现以上错误。
Function * not registered
错误描述
函数不存在。
报错原因
您指定的函数在SLS SQL系统中不存在,这可能是以下情况:
您使用了某数据库厂商的特定函数,该函数并非标准SQL函数,在SLS SQL系统并未提供。
您拼写错了函数名称。
解决方法
请检查函数名称,确认是SLS SQL提供的有效函数。
SQL array indices start at 1
错误描述
SQL数组索引位置从1开始。
报错原因
您在SQL使用数组索引位置时,可能从0开始计数。
解决方法
SQL数组索引位置从1开始计数。
Index must be greater than zero
错误描述
索引位置从1开始。
报错原因
您在SQL使用数组索引位置时,可能指定了无效的负值或者0。
解决方法
SQL数组索引位置从1开始计数。
All COALESCE operands must be the same type: *
错误描述
COALESCE函数中的所有参数必须类型一致。
报错原因
在COALESCE函数中,操作数必须具有相同的数据类型,否则会出现数据类型错误。在此错误中,操作数中至少有一个是布尔类型,而其他操作数则具有不同的数据类型,例如数字、字符串等。
解决方法
请检查COALESCE函数中的每个操作数,并确保它们具有相同的数据类型。如果数据类型不同,请进行数据类型转换,以使它们具有相同的数据类型。可以使用CAST函数执行数据类型转换。
Multiple columns returned by subquery are not yet supported.
错误描述
标量查询不支持返回多个列。
报错原因
在子查询中SELECT了多个列。
解决方法
确保子查询只返回一列或一个值,可以修改子查询或主查询。另外,还可以尝试使用JOIN语句代替子查询来检索所需的数据。
GROUP BY clause cannot contain aggregations or window functions: *
错误描述
GROUP BY子句不能包含聚合函数或窗口函数。
报错原因
在GROUP BY子句中包含聚合函数或窗口函数。
解决方法
请在GROUP BY子句中只包含列名,而不是聚合函数或窗口函数。聚合函数和窗口函数应该在SELECT语句中使用,而不是在GROUP BY子句中使用。如果您需要在GROUP BY子句中使用聚合函数,则可以使用列的别名或数字索引来代替聚合函数。例如,使用以下查询:
SELECT column1, column2, COUNT(column3) as count_column3 FROM table GROUP BY column1, column2, 3在这个查询中,count_column3 是 COUNT(column3) 的别名,3 是 COUNT(column3) 在SELECT语句中的位置。请注意,使用数字索引可能会使代码难以理解,建议使用列别名。
WHERE BY clause cannot contain aggregations or window functions: *
错误描述
WHERE子句不能包含聚合函数或窗口函数。
报错原因
在WHERE子句中包含聚合函数或窗口函数。
解决方法
请在WHERE子句中只包含列名,而不是聚合函数或窗口函数。聚合函数和窗口函数应该在SELECT语句中使用,而不是在WHERE子句中使用。如果您需要在WHERE子句中使用聚合函数,则可以使用列的别名来代替聚合函数。
例如,使用以下查询:
SELECT column1, column2, COUNT(column3) as count_column3 FROM table WHERE count_column3 > 10在这个查询中,count_column3 是 COUNT(column3) 的别名,它代表column3的聚合计数结果。
Left side of LIKE expression must evaluate to a varchar (actual: bigint)
错误描述
LIKE表达式左侧必须为varchar类型(实际为bigint)。
报错原因
该错误通常发生在您尝试使用LIKE运算符比较bigint数据类型与varchar数据类型时。 LIKE运算符要求表达式的两侧具有相同的数据类型。
解决方法
您可能需要使用CAST函数将bigint转换为varchar。
SELECT * FROM table WHERE CAST(bigint_column AS varchar) LIKE 'pattern'这将会把bigint_column转换为varchar,然后可以使用LIKE运算符将其与指定模式进行匹配。
Left side of logical expression must evaluate to a boolean (actual: varchar)
错误描述
逻辑表达式左侧必须为boolean类型(实际为varchar)。
报错原因
该错误通常发生在您尝试使用逻辑表达式时,关系运算符
=或!=等右侧是boolean类型值(true或false),但左侧类型是非boolean类型,可能是varchar等其他类型。解决方法
您需要检查逻辑表达式左侧的值类型,确保是boolean类型。
Right side of logical expression must evaluate to a boolean (actual: bigint)
错误描述
逻辑表达式右侧必须为boolean类型(实际为bigint)。
报错原因
该错误通常发生在您尝试使用逻辑表达式时,逻辑表达式右侧的变量类型不是boolean。
解决方法
您需要检查逻辑表达式右侧的值类型,确保是boolean类型。
Invalid JSON path: ...
错误描述
非法JSON访问路径。
报错原因
您在SQL中使用JSON函数(如json_extract、json_extract_scalar、json_size等)访问指定的JSON路径时,未指定有效路径。
解决方法
正常指定json_path,格式为
$.a.b。其中$代表当前JSON对象的根节点,半角句号.引用到待提取的节点(可级联),但是当JSON对象的字段中存在特殊字符(如.、空格-等),例如 http.path、http path、http-path等,则需要使用中括号[]代替半角句号.,然后使用双引号""包裹字段名,例如:* | SELECT json_extract_scalar(request, '$["X-Power-Open-App-Id"]')您可以参考JSON函数使用说明,了解JSON函数和json_path的具体用法。您还可以参考查询和分析JSON日志的常见问题了解json_path的具体使用方式。
max distinct num is:10, please use approx_distinct
错误描述
单个Query中限制最多使用10个distinct。
报错原因
您在SQL中使用了超过10个distinct计算。
解决方法
减少SQL中使用的distinct数量到10个以下。
使用approx_distinct替换distinct。
Key not present in map
错误描述
Map中不存在指定key。
报错原因
您在SQL中使用了map类型,并指定了一个不存在的key。
解决方法
检查map类型数据,确认您指定的key在map中存在。
如果map类型数据中有可能不存在该key,您可以使用try函数将map访问包裹,以忽略该错误,例如:
SELECT try(map['name']) -- map是一个map类型列,如果该列中不存在名为'name'的key,则返回NULL
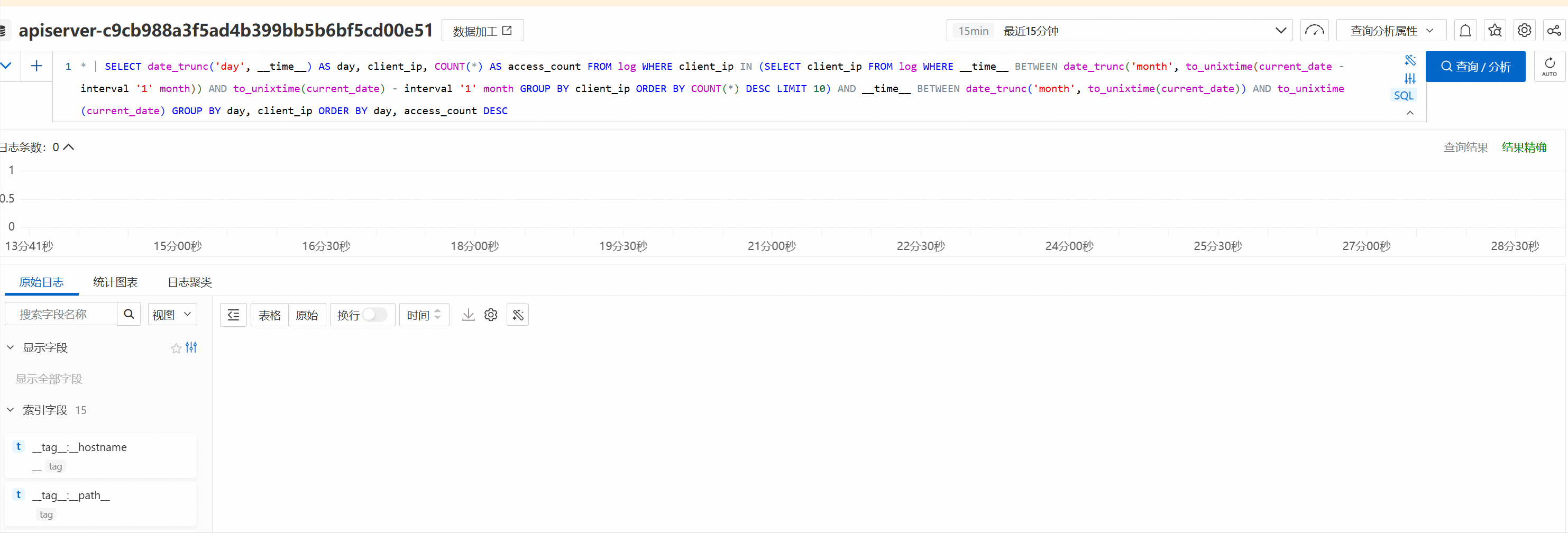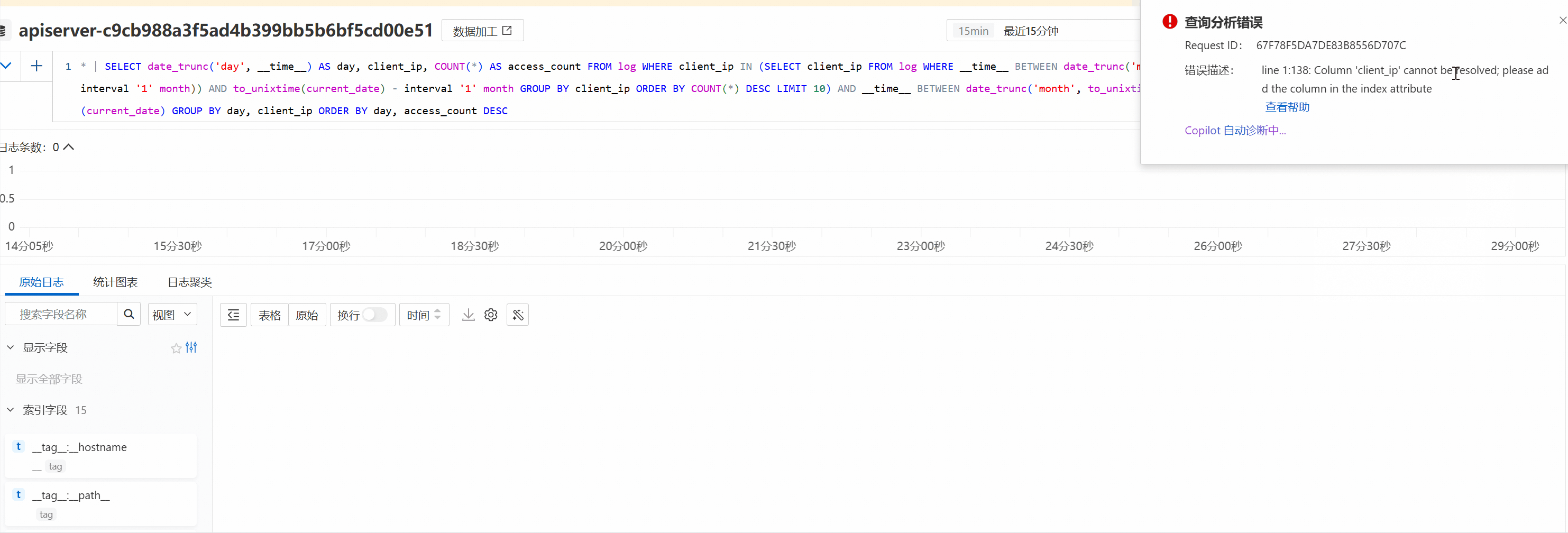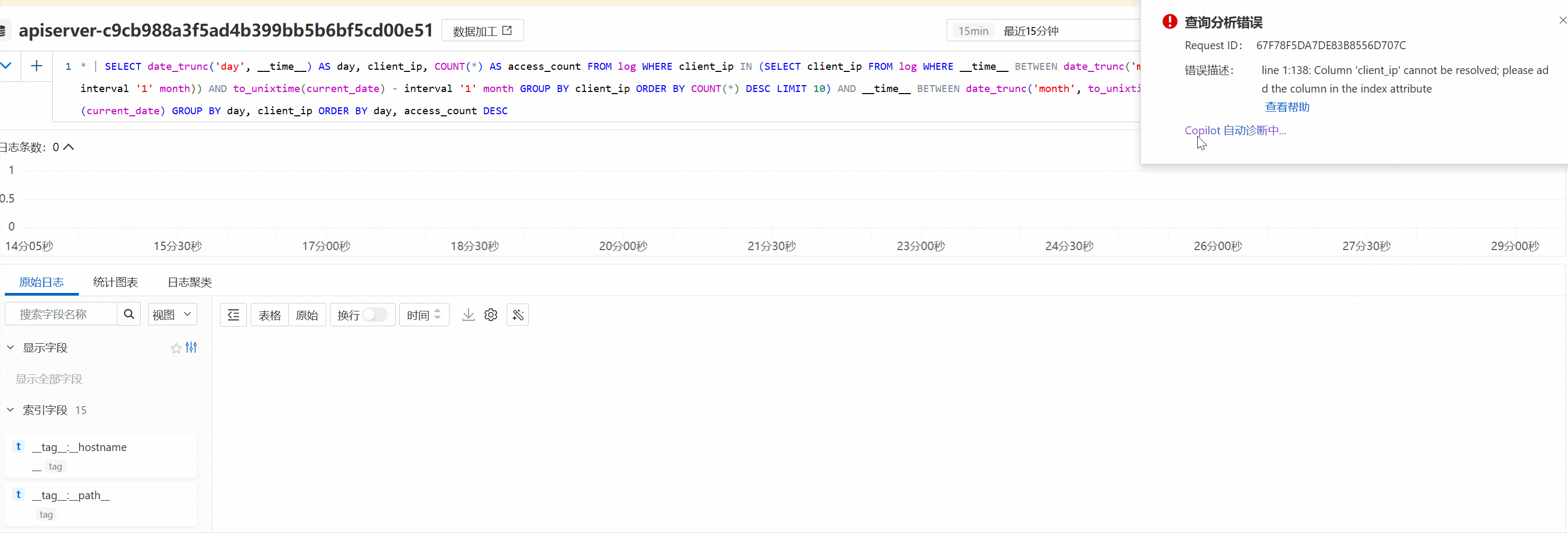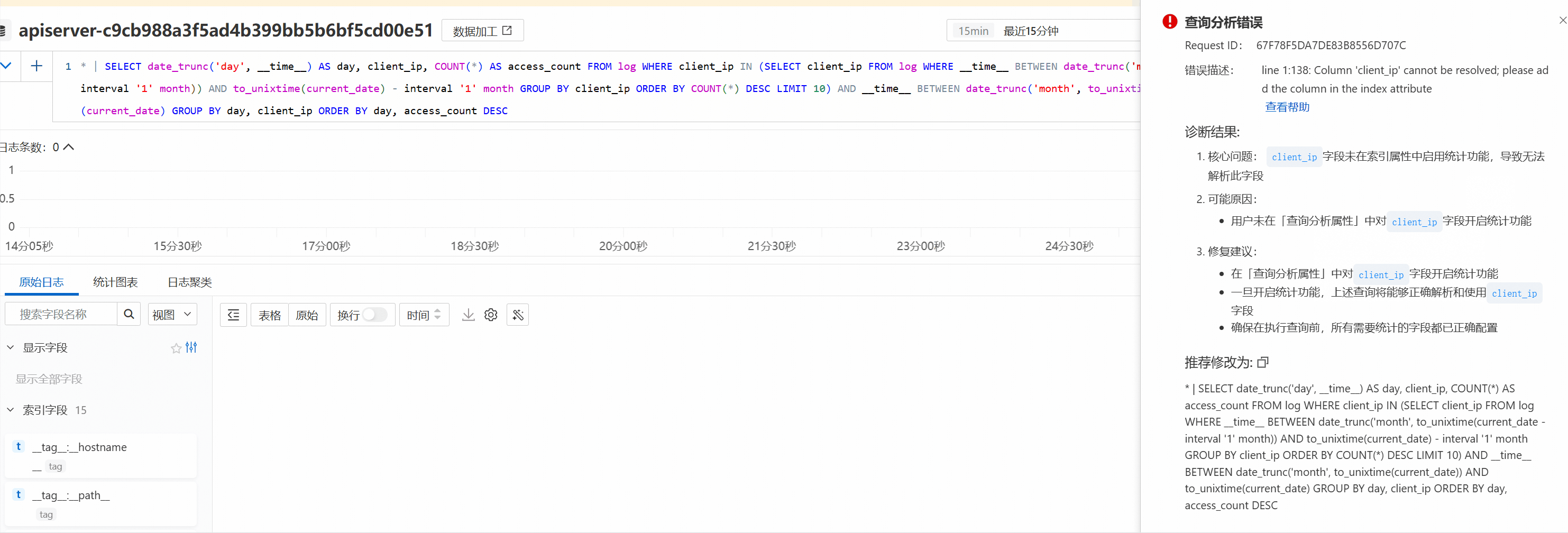
line 1:44: Column 'XXX' cannot be resolved;please add the column in the index attribute
报错原因
未对XXX字段建立索引。
解决方法
为目标字段设置索引,并开启统计功能。具体操作,请参见创建索引。
ErrorType:QueryParseError.ErrorMessage:syntax error error position is from column:10 to column:11,error near < : >
报错原因
查询和分析语句的语法错误,错误位置在冒号(:)附近。
解决方法
检查及修改查询和分析语句,然后重新执行。
Column 'XXX' not in GROUP BY clause;please add the column in the index attribute
报错原因
在SQL语句中,如果您使用了GROUP BY子句,则在执行SELECT语句时,只能选择GROUP BY的列或者对任意列进行聚合计算,不允许选择非GROUP BY的列。例如
* | SELECT status, request_time, COUNT(*) AS PV GROUP BY status为非法分析语句,因为request_time不是GROUP BY的列。解决方法
修改查询和分析语句,然后重新执行。例如上述示例的正确语句为
* | SELECT status, arbitrary(request_time), count(*) AS PV GROUP BY status。更多信息,请参见GROUP BY子句。
sql query must follow search query,please read syntax doc
报错原因
仅使用了分析语句。在日志服务中,分析语句必须与查询语句一起使用,格式为
查询语句|分析语句。解决方法
在分析语句前加上查询语句,例如
* | SELECT status, count(*) AS PV GROUP BY status。更多信息,请参见基础语法。
line 1:10: identifiers must not start with a digit; surround the identifier with double quotes
报错原因
分析语句中的列名、变量名等以数字开头,不符合规范。在SQL标准中,列名必须由字母、数字和下划线(_)组成,且以字母开头。
解决方法
更改别名。如何修改,请参见列的别名。
line 1:9: extraneous input ‘’ expecting
报错原因
输入了多余的中文引号。
解决方法
检查及修改查询和分析语句,然后重新执行。
key (XXX) is not config as key value config,if symbol : is in your log,please wrap : with quotation mark "
报错原因
未对XXX字段建立字段索引,或者您所使用的字段中包含了特殊字符(例如空格)但未使用双引号("")包裹。
解决方法
确认是否已为目标字段创建字段索引且开启统计功能。
如果是,请执行下一步。
如果不是,请先为目标字段创建字段索引且开启统计功能。具体操作,请参见手动创建字段索引。
执行该操作后,如果问题解决,则无需执行下一步。
使用双引号("")包裹目标字段。
Query exceeded max memory size of 3GB
报错原因
当前查询和分析语句所使用的服务端内存超过3 GB。该问题通常是因为使用GROUP BY子句去重后,值太多导致的。
解决方法
优化GROUP BY子句,减少GROUP BY子句中字段的个数。
ErrorType:ColumnNotExists.ErrorPosition,line:0,column:1.ErrorMessage:line 1:123: Column 'XXX' cannot be resolved; it seems XXX is wrapper by ";if XXX is a string ,not a key field, please use 'XXX'
报错原因
XXX不是索引字段,不能使用双引号("")包裹。在分析语句中,表示字符串的字符必须使用单引号('')包裹,无符号包裹或被双引号("")包裹的字符表示字段名或列名。
解决方法
如果XXX为分析字段,您需要为该字段配置索引,并开启统计功能。具体操作,请参见创建索引。
如果XXX为普通字符串,需要使用单引号('')包裹。
user can only run 15 query concurrently
报错原因
分析操作并发数超过了15个。在日志服务中,单个Project支持的最大分析操作并发数为15个。
解决方法
合理控制分析操作的并发数。
unclosed string quote
报错原因
查询和分析语句的双引号(")未成对出现。
解决方法
检查及修改查询和分析语句,然后重新执行。
error after :.error detail:error after :.error detail:line 1:147: mismatched input 'in' expecting {<EOF>, 'GROUP', 'ORDER', 'HAVING', 'LIMIT', 'OR', 'AND', 'UNION', 'EXCEPT', 'INTERSECT'}
报错原因
输入了错误的关键词in。
解决方法
检查及修改查询和分析语句,然后重新执行。
Duplicate keys (XXX) are not allowed
报错原因
建立索引时,为字段配置了重复的索引。
解决方法
检查您的索引配置。具体操作,请参见创建索引。
only support * or ? in the middle or end of the query
报错原因
使用模糊查询时,未正确使用通配符。
解决方法
修改查询和分析语句中的通配符。相关说明如下:
支持在词的中间或者末尾加上模糊查询关键字,即星号(*)或问号(?)。
星号(*)或问号(?)不能用在词的开头。
long数据类型和double数据类型不支持使用星号(*)或问号(?)进行模糊查询。
logstore (xxx) is not found
报错原因
日志库XXX不存在或未配置索引。
解决方法
请检查对应的日志库是否存在。如果存在,请确保至少存在一个字段索引且开启统计功能。
condition number 43 is more than 30
报错原因
您在查询语句中使用的字段数为43个,超过日志服务所限制的30个。
解决方法
请修改查询语句,将字段数量控制在30个以内。
ErrorType:SyntaxError.ErrorPosition,line:1,column:19.ErrorMessage:line 1:19: Expression "data" is not of type ROW
报错原因
查询和分析语句中所使用的字段的数据类型错误。
解决方法
请检查ROW函数的参数是否正确,并且参数中所有的字段是否存在且符合要求。如果参数正确,但结果仍然不是ROW类型,可以尝试使用CAST函数将其转换为ROW类型。
ErrorType:SyntaxError.ErrorPosition,line:1,column:9.ErrorMessage:line 1:9: identifiers must not contain ':'
报错原因
您所分析的字段中包含了半角冒号(:)。
解决方法
使用半角双引号("")包裹字段。例如您要分析
__tag__:__receive_time__字段,可使用语句*| select "__tag__:__receive_time__"。重要在分析字段前,必须先创建字段索引。具体操作,请参见手动创建字段索引。
No nodes available to run query
报错原因
系统内部错误。
解决方法
请刷新页面,重新执行查询和分析语句。