
时序聚类函数针对输入的多条时序数据进行聚类,自动聚类出不同的曲线形态,进而快速找到相应的聚类中心和异于聚类中的其它形态曲线。
关于函数的算法及实现原理请参见LOG机器学习介绍(02):时序聚类建模。
函数列表
函数 | 说明 |
| 使用密度聚类方法对多条时序数据进行聚类。 |
| 使用层次聚类方法对多条时序数据进行聚类。 |
| 查找到指定曲线名称的相似曲线。 |
ts_density_cluster
函数格式如下所示:
select ts_density_cluster(x, y, z) 参数说明如下所示:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | 无 |
z | 某个时刻数据对应的曲线名称。 | 字符串类型,例如machine01.cpu_usr。 |
示例:
查询分析语句如下所示:
* and (h: "machine_01" OR h: "machine_02" OR h : "machine_03") | select ts_density_cluster(stamp, metric_value,metric_name ) from ( select '("__time__" - ("__time__" % 600))' as stamp, avg(v) as metric_value, h as metric_name from log GROUP BY stamp, metric_name order BY metric_name, stamp )输出结果如下所示:
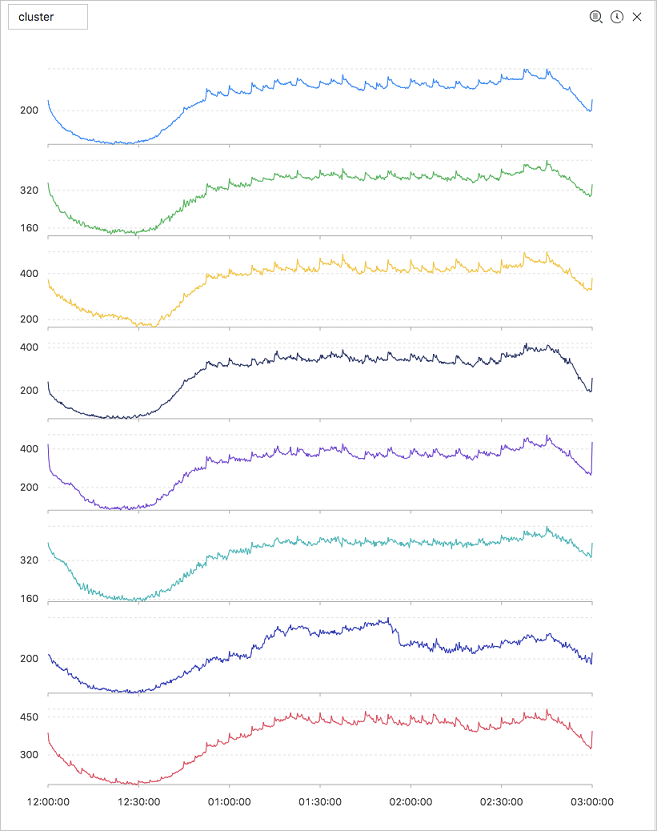
显示项如下所示:
显示项 | 说明 |
cluster_id | 聚类的类别,其中-1表示未能划分到某一聚类中心。 |
rate | 该聚类中的instance占比。 |
time_series | 该聚类中心的时间戳序列。 |
data_series | 该聚类中心的数据序列。 |
instance_names | 该聚类中心包含的instance的集合。 |
sim_instance | 该类中的某一个instance名称。 |
ts_hierarchical_cluster
函数格式如下所示:
select ts_hierarchical_cluster(x, y, z) 参数说明如下所示:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | 无 |
z | 某个时刻数据对应的曲线名称。 | 字符串类型,例如machine01.cpu_usr。 |
示例:
查询分析语句如下所示:
* and (h: "machine_01" OR h: "machine_02" OR h : "machine_03") | select ts_hierarchical_cluster(stamp, metric_value, metric_name) from ( select '("__time__" - ("__time__" % 600))' as stamp, avg(v) as metric_value, h as metric_name from log GROUP BY stamp, metric_name order BY metric_name, stamp )输出结果如下所示:
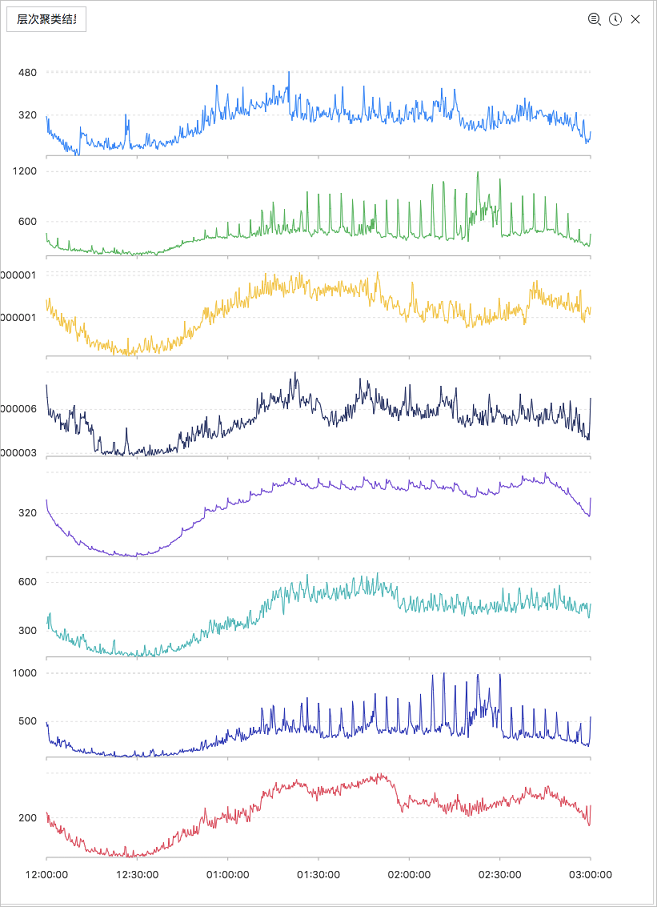
显示项如下所示:
显示项 | 说明 |
cluster_id | 聚类的类别,其中-1表示未能划分到某一聚类中心。 |
rate | 该聚类中的instance占比。 |
time_series | 该聚类中心的时间戳序列。 |
data_series | 该聚类中心的数据序列。 |
instance_names | 该聚类中心包含的instance的集合。 |
sim_instance | 该类中的某一个instance名称。 |
ts_similar_instance
函数格式如下所示:
select ts_similar_instance(x, y, z,instance_name,topK,metricType) 参数说明如下所示:
参数 | 说明 | 取值 |
x | 时间列,从小到大排列。 | 格式为Unixtime时间戳,单位为秒。 |
y | 数值列,对应某时刻的数据。 | 无 |
z | 某个时刻数据对应的曲线名称。 | 字符串类型,例如machine01.cpu_usr。 |
instance_name | 指定某个待查找的曲线名称。 | 集合中某个曲线名称,字符串类型,例如machine01.cpu_usr。 说明 必须是已创建的曲线。 |
topK | 最多返回K个与给定曲线相似的曲线。 | 无 |
metricType |
| 无 |
查询分析语句如下所示:
* and m: NET and m: Tcp and (h: "nu4e01524.nu8" OR h: "nu2i10267.nu8" OR h : "nu4q10466.nu8") | select ts_similar_instance(stamp, metric_value, metric_name, 'nu4e01524.nu8' ) from ( select '("__time__" - ("__time__" % 600))' as stamp, sum(v) as metric_value, h as metric_name from log GROUP BY stamp, metric_name order BY metric_name, stamp )显示项如下所示:
显示项 | 说明 |
instance_name | 与指定指标相近的结果列表。 |
time_series | 该曲线的时间戳序列。 |
data_series | 该曲线的数据序列。 |