
HDP(Hortonworks Data Platform)是由Hortonworks发行的大数据平台,包含了Hadoop、Hive、HBase等开源组件。HDP 3.0.1版本中的Hadoop 3.1.1版本已支持OSS,但是低版本的HDP不支持OSS。本文以HDP 2.6.1.0版本为例,介绍如何配置HDP 2.6版本支持读写OSS。
前提条件
已搭建HDP 2.6.1.0的集群。如果未搭建HDP 2.6.1.0集群,您可以通过以下方式搭建:
- 使用Ambari搭建HDP 2.6.1.0的集群。
- 不使用Ambari,自行搭建HDP 2.6.1.0集群。
配置步骤
- 下载HDP 2.6.1.0版本支持OSS的支持包。
- 执行以下命令解压支持包。
sudo tar -xvf hadoop-oss-hdp-2.6.1.0-129.tar成功返回示例如下。
hadoop-oss-hdp-2.6.1.0-129/ hadoop-oss-hdp-2.6.1.0-129/aliyun-java-sdk-ram-3.0.0.jar hadoop-oss-hdp-2.6.1.0-129/aliyun-java-sdk-core-3.4.0.jar hadoop-oss-hdp-2.6.1.0-129/aliyun-java-sdk-ecs-4.2.0.jar hadoop-oss-hdp-2.6.1.0-129/aliyun-java-sdk-sts-3.0.0.jar hadoop-oss-hdp-2.6.1.0-129/jdom-1.1.jar hadoop-oss-hdp-2.6.1.0-129/aliyun-sdk-oss-3.4.1.jar hadoop-oss-hdp-2.6.1.0-129/hadoop-aliyun-2.7.3.2.6.1.0-129.jar - 调整JAR文件的目录。说明 本文中所有${}的内容为环境变量,请您根据实际环境修改。
- 将hadoop-aliyun-2.7.3.2.6.1.0-129.jar移至${/usr/hdp/current}/hadoop-client/目录,然后执行以下命令验证调整后的目录。
sudo ls -lh /usr/hdp/current/hadoop-client/hadoop-aliyun-2.7.3.2.6.1.0-129.jar成功返回示例如下。
-rw-r--r-- 1 root root 64K Oct 28 20:56 /usr/hdp/current/hadoop-client/hadoop-aliyun-2.7.3.2.6.1.0-129.jar - 将其他的jar文件移至${/usr/hdp/current}/hadoop-client/lib/目录,然后执行以下命令验证调整后的目录。
sudo ls -ltrh /usr/hdp/current/hadoop-client/lib成功返回示例如下。
total 27M ...... drwxr-xr-x 2 root root 4.0K Oct 28 20:10 ranger-hdfs-plugin-impl drwxr-xr-x 2 root root 4.0K Oct 28 20:10 ranger-yarn-plugin-impl drwxr-xr-x 2 root root 4.0K Oct 28 20:10 native -rw-r--r-- 1 root root 114K Oct 28 20:56 aliyun-java-sdk-core-3.4.0.jar -rw-r--r-- 1 root root 513K Oct 28 20:56 aliyun-sdk-oss-3.4.1.jar -rw-r--r-- 1 root root 13K Oct 28 20:56 aliyun-java-sdk-sts-3.0.0.jar -rw-r--r-- 1 root root 211K Oct 28 20:56 aliyun-java-sdk-ram-3.0.0.jar -rw-r--r-- 1 root root 770K Oct 28 20:56 aliyun-java-sdk-ecs-4.2.0.jar -rw-r--r-- 1 root root 150K Oct 28 20:56 jdom-1.1.jar
- 将hadoop-aliyun-2.7.3.2.6.1.0-129.jar移至${/usr/hdp/current}/hadoop-client/目录,然后执行以下命令验证调整后的目录。
- 在所有的HDP节点执行以上操作。
- 通过Ambari来增加配置。没有使用Ambari管理的集群,可以修改core-site.xml。这里以Ambari为例,需要增加如下配置。
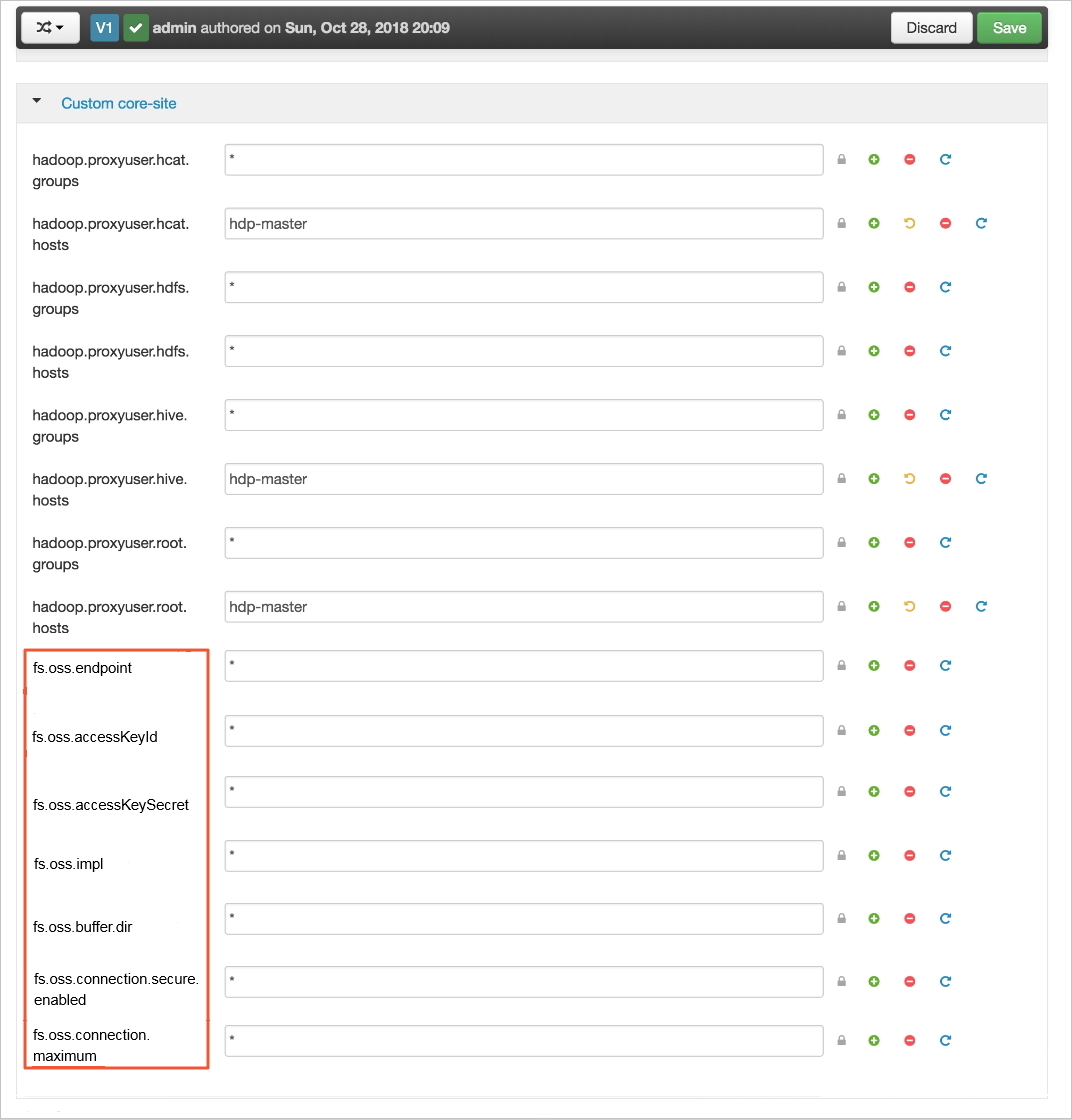
参数 说明 fs.oss.endpoint 填写需要连接的OSS的Endpoint。 例如:oss-cn-zhangjiakou-internal.aliyuncs.com
fs.oss.accessKeyId 填写OSS的AccessKeyId。 fs.oss.accessKeySecret 填写OSS的AccessKeySecret。 fs.oss.impl Hadoop OSS文件系统实现类。目前固定为:org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem fs.oss.buffer.dir 填写临时文件目录。 建议值:/tmp/oss
fs.oss.connection.secure.enabled 是否开启HTTPS。开启HTTPS会影响性能。 建议值:false
fs.oss.connection.maximum 与OSS的连接数。 建议值:2048
更多参数,请参见Hadoop-Aliyun module。
- 根据Ambari提示重启集群。
- 测试读写OSS。
- 执行以下命令测试读。
sudo hadoop fs -ls oss://${your-bucket-name}/ - 执行以下命令测试写。
sudo hadoop fs -mkdir oss://${your-bucket-name}/hadoop-test如果测试可以读写OSS,则配置成功。如果无法读写OSS,请检查配置。
- 执行以下命令测试读。
- 为了能够运行MapReduce任务,执行以下命令将OSS支持包移动到hdfs://hdp-master:8020/hdp/apps/2.6.1.0-129/mapreduce/mapreduce.tar.gz压缩包下。说明 本文以MapReduce类型的作业为例。其他类型的作业的压缩包可参考以下操作修改。例如,如果是TEZ类型的作业,则将OSS支持包移动到hdfs://hdp-master:8020/hdp/apps/2.6.1.0-129/tez/tez.tar.gz压缩包下。
sudo su hdfs sudo cd sudo hadoop fs -copyToLocal /hdp/apps/2.6.1.0-129/mapreduce/mapreduce.tar.gz sudo hadoop fs -rm /hdp/apps/2.6.1.0-129/mapreduce/mapreduce.tar.gz sudo cp mapreduce.tar.gz mapreduce.tar.gz.bak sudo tar zxf mapreduce.tar.gz sudo cp /usr/hdp/current/hadoop-client/hadoop-aliyun-2.7.3.2.6.1.0-129.jar hadoop/share/hadoop/tools/lib/ sudo cp /usr/hdp/current/hadoop-client/lib/aliyun-* hadoop/share/hadoop/tools/lib/ sudo cp /usr/hdp/current/hadoop-client/lib/jdom-1.1.jar hadoop/share/hadoop/tools/lib/ sudo tar zcf mapreduce.tar.gz hadoop sudo hadoop fs -copyFromLocal mapreduce.tar.gz /hdp/apps/2.6.1.0-129/mapreduce/
验证配置
可通过测试teragen和terasort,来检测配置是否生效。
- 执行以下命令测试teragen。
sudo hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar teragen -Dmapred.map.tasks=100 10995116 oss://{bucket-name}/1G-input成功返回示例如下。
18/10/28 21:32:38 INFO client.RMProxy: Connecting to ResourceManager at cdh-master/192.168.0.161:8050 18/10/28 21:32:38 INFO client.AHSProxy: Connecting to Application History server at cdh-master/192.168.0.161:10200 18/10/28 21:32:38 INFO aliyun.oss: [Server]Unable to execute HTTP request: Not Found [ErrorCode]: NoSuchKey [RequestId]: 5BD5BA7641FCE369BC1D052C [HostId]: null 18/10/28 21:32:38 INFO aliyun.oss: [Server]Unable to execute HTTP request: Not Found [ErrorCode]: NoSuchKey [RequestId]: 5BD5BA7641FCE369BC1D052F [HostId]: null 18/10/28 21:32:39 INFO terasort.TeraSort: Generating 10995116 using 100 18/10/28 21:32:39 INFO mapreduce.JobSubmitter: number of splits:100 18/10/28 21:32:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1540728986531_0005 18/10/28 21:32:39 INFO impl.YarnClientImpl: Submitted application application_1540728986531_0005 18/10/28 21:32:39 INFO mapreduce.Job: The url to track the job: http://cdh-master:8088/proxy/application_1540728986531_0005/ 18/10/28 21:32:39 INFO mapreduce.Job: Running job: job_1540728986531_0005 18/10/28 21:32:49 INFO mapreduce.Job: Job job_1540728986531_0005 running in uber mode : false 18/10/28 21:32:49 INFO mapreduce.Job: map 0% reduce 0% 18/10/28 21:32:55 INFO mapreduce.Job: map 1% reduce 0% 18/10/28 21:32:57 INFO mapreduce.Job: map 2% reduce 0% 18/10/28 21:32:58 INFO mapreduce.Job: map 4% reduce 0% ... 18/10/28 21:34:40 INFO mapreduce.Job: map 99% reduce 0% 18/10/28 21:34:42 INFO mapreduce.Job: map 100% reduce 0% 18/10/28 21:35:15 INFO mapreduce.Job: Job job_1540728986531_0005 completed successfully 18/10/28 21:35:15 INFO mapreduce.Job: Counters: 36 ... - 执行以下命令测试terasort。
sudo hadoop jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-mapreduce-examples.jar terasort -Dmapred.map.tasks=100 oss://{bucket-name}/1G-input oss://{bucket-name}/1G-output成功返回示例如下。
18/10/28 21:39:00 INFO terasort.TeraSort: starting ... 18/10/28 21:39:02 INFO mapreduce.JobSubmitter: number of splits:100 18/10/28 21:39:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1540728986531_0006 18/10/28 21:39:02 INFO impl.YarnClientImpl: Submitted application application_1540728986531_0006 18/10/28 21:39:02 INFO mapreduce.Job: The url to track the job: http://cdh-master:8088/proxy/application_1540728986531_0006/ 18/10/28 21:39:02 INFO mapreduce.Job: Running job: job_1540728986531_0006 18/10/28 21:39:09 INFO mapreduce.Job: Job job_1540728986531_0006 running in uber mode : false 18/10/28 21:39:09 INFO mapreduce.Job: map 0% reduce 0% 18/10/28 21:39:17 INFO mapreduce.Job: map 1% reduce 0% 18/10/28 21:39:19 INFO mapreduce.Job: map 2% reduce 0% 18/10/28 21:39:20 INFO mapreduce.Job: map 3% reduce 0% ... 18/10/28 21:42:50 INFO mapreduce.Job: map 100% reduce 75% 18/10/28 21:42:53 INFO mapreduce.Job: map 100% reduce 80% 18/10/28 21:42:56 INFO mapreduce.Job: map 100% reduce 86% 18/10/28 21:42:59 INFO mapreduce.Job: map 100% reduce 92% 18/10/28 21:43:02 INFO mapreduce.Job: map 100% reduce 98% 18/10/28 21:43:05 INFO mapreduce.Job: map 100% reduce 100% ^@18/10/28 21:43:56 INFO mapreduce.Job: Job job_1540728986531_0006 completed successfully 18/10/28 21:43:56 INFO mapreduce.Job: Counters: 54 ...
测试成功,配置生效。