
您在购买部分Alibaba Cloud Linux 3操作系统的倚天实例、AMD实例或Intel实例时,可以选择安装性能加速类扩展程序。选中后,系统会在实例上自动安装所选应用(例如Nginx、MySQL、Redis等),并同步安装KeenTune工具对应用进行性能调优,使应用获得平均20%左右的性能提升。本文主要介绍如何安装性能加速应用、应用的性能收益、如何卸载应用以及如何关闭性能加速能力。
关于KeenTune的更多信息,请参见KeenTune。
功能说明
创建实例时部署了支持性能加速的应用后,KeenTune会针对该应用的业务特点进行全栈的性能调优。这些调优集合了阿里云在多个领域及业务的调优经验积累,不仅针对实例的特点对CPU、内存、I/O、网络等领域进行了全面优化,也会对应用本身进行调优,来保障您的业务运行在最佳性能环境中,并能使Nginx、MySQL、Redis、PostgreSQL等应用获得平均20%左右的性能提升,助力您实现降本增效的目标。默认安装的应用版本及性能收益,请参见默认安装的应用版本及性能提升。
适用实例
性能加速类扩展程序,仅适用于部分Alibaba Cloud Linux 3操作系统的倚天实例、AMD实例和Intel实例。
实例类型 | 规格族 | 操作系统 |
倚天实例 |
| Alibaba Cloud Linux 3 |
AMD实例 |
| |
Intel实例 |
|
新购ECS实例
如果您是新购ECS实例,可以在创建ECS实例过程中安装应用并配置性能加速。购买实例之后,只能通过命令行方式关闭性能加速能力或卸载已安装的应用。
安装应用性能加速
前往实例购买页。
购买倚天实例、AMD实例或Intel实例时,安装性能加速类扩展程序。
购买时,请注意以下配置。其他参数配置,请参见自定义购买实例。
倚天实例
实例:选择倚天实例。具体支持的实例规格,请参见适用实例。
镜像:Alibaba Cloud Linux 3。
扩展程序:
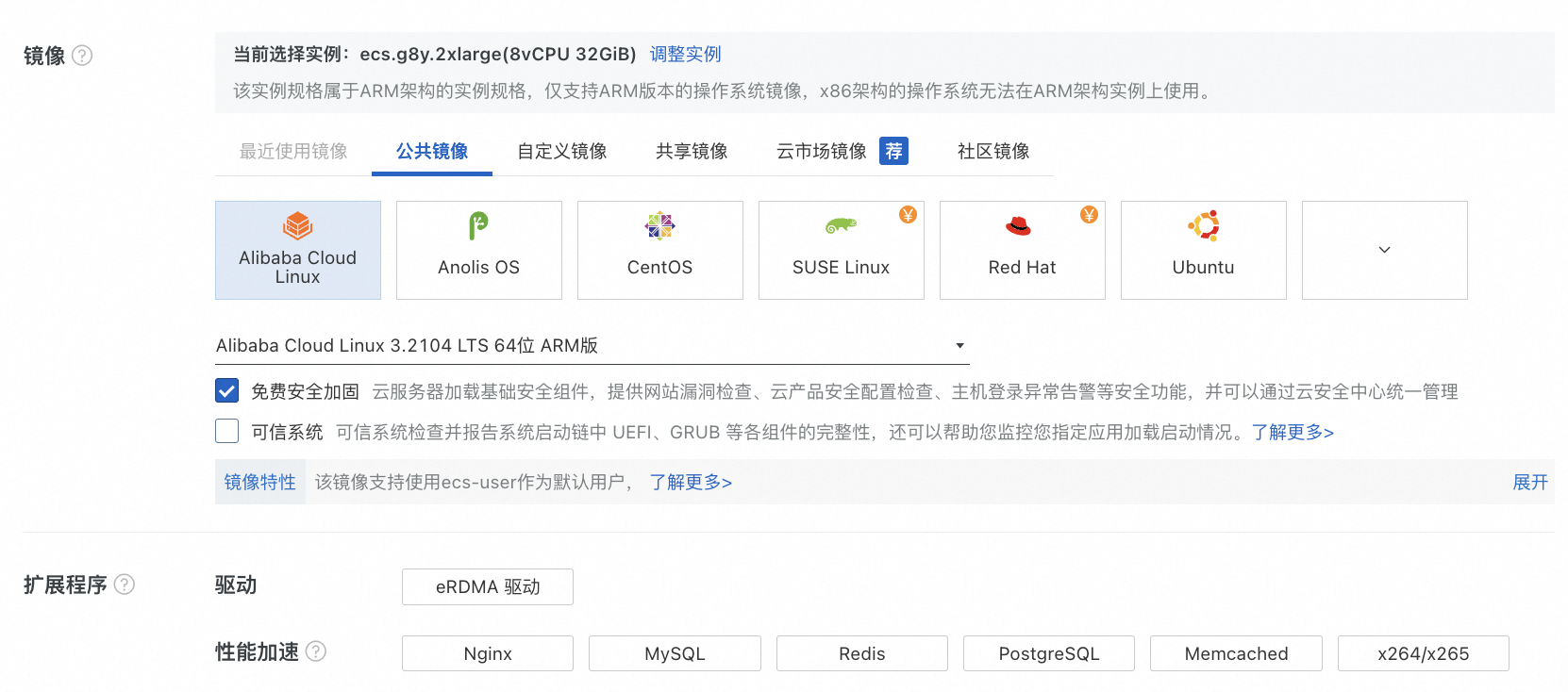
驱动:如果您的实例需要配置eRDMA,需选中eRDMA驱动,实例启动过程中会自动安装eRDMA驱动,无需您再手动安装。
性能加速:根据需要选择要安装的应用(例如Nginx、MySQL、Redis等)。
默认安装的应用版本及性能提升说明请参见默认安装的应用版本及性能提升。
说明支持安装的应用,以页面实际呈现为准。
Spark性能加速扩展不支持在创建实例时安装,仅支持在创建实例后在实例详情页安装。
启用eRDMA透明替换(可选):应用选择Redis,且操作系统内核版本≥5.10.134-16时,支持启用eRDMA透明替换,将Redis的传输层协议从TCP切换到RDMA,提升网络性能。
重要eRDMA透明替换技术基于共享内存通信(SMC)实现,启用后,部分用户运维工具将不可用。更多信息,请参见共享内存通信(SMC)常见问题和共享内存通信(SMC)使用说明。
请勿同时选中eRDMA驱动和启动eRDMA透明替换,否则会卸载并安装新的eRDMA驱动,从而导致eRDMA透明替换失效。
关闭eRDMA透明替换:购买实例之后,如不再需要使用该功能,关闭性能加速即可关闭eRDMA透明替换。具体操作,请参见关闭性能加速能力。
弹性网卡(条件必选):若选中启用eRDMA透明替换,需在弹性网卡处,勾选弹性RDMA接口。
AMD实例
实例:选择AMD实例。具体支持的实例规格,请参见适用实例。
镜像:Alibaba Cloud Linux 3。
扩展程序:
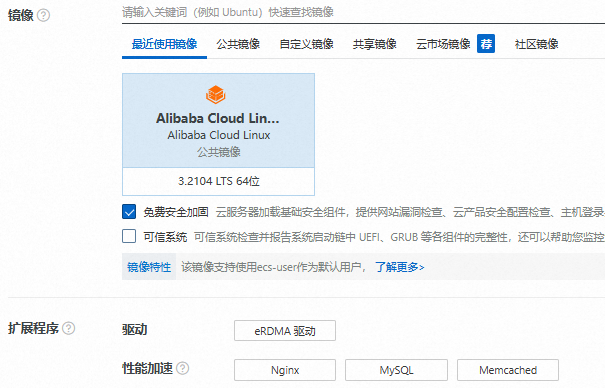
驱动:如果您的实例需要配置eRDMA,需选中eRDMA驱动,实例启动过程中会自动安装eRDMA驱动,无需您再手动安装。
性能加速:根据需要选择要安装的应用(例如Nginx、MySQL、Memcached)。
默认安装的应用版本及性能提升说明请参见默认安装的应用版本及性能提升。
说明支持安装的应用,以页面实际呈现为准。
Intel实例
实例:选择Intel实例。具体支持的实例规格,请参见适用实例。
镜像:Alibaba Cloud Linux 3。
扩展程序:
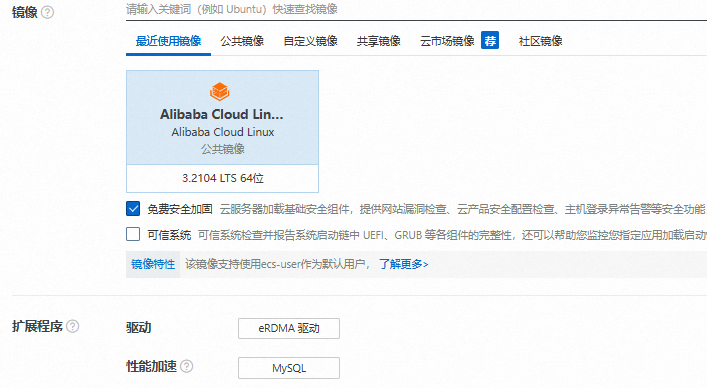
驱动:如果您的实例需要配置eRDMA,需选中eRDMA驱动,实例启动过程中会自动安装eRDMA驱动,无需您再手动安装。
性能加速:仅支持选择安装MySQL应用。
默认安装的应用版本及性能提升说明请参见默认安装的应用版本及性能提升。
实例创建成功后,系统会自动安装选择的应用,并使用KeenTune针对该应用的业务特点进行全栈性能调优。
关闭性能加速能力
购买实例之后,如果不需要性能加速能力,可以单独卸载KeenTune关闭性能加速,保留已安装的应用。
性能加速主要针对单一应用部署场景,如果您是混合部署场景,建议您在使用混合部署方式之前,参考如下命令关闭性能加速能力。
关闭性能加速能力后,会同步关闭eRDMA透明替换能力。
sudo bash /etc/keentune/target/scripts/set_xps_rps.sh eth0 rps disable
sudo keentune profile rollback
sudo systemctl stop keentune-target keentuned
sudo yum remove keentune-target keentuned卸载默认安装的应用
购买实例之后,如果不需要使用默认安装的应用程序,可以单独卸载默认安装的应用程序,并保留性能加速能力。重新安装并启用应用程序后,程序仍具有性能加速能力。
sudo systemctl stop <APP_Name>
sudo yum remove <APP_Name><APP_Name>请替换为实际的应用名称,例如Nginx。
存量ECS实例
如果您是存量的Alibaba Cloud Linux 3操作系统的倚天实例(g8y、c8y、r8y),可以在实例详情页面选择安装或卸载应用性能加速。
支持安装的应用性能加速:x264/x265、Nginx、Spark性能加速扩展。
重要Spark性能加速扩展功能在邀测中,如需使用,请联系您的商务经理开通。
Spark性能加速扩展仅支持ecs.g8y.8xlarge及以上规格和ecs.r8y.8xlarge及以上规格。
Spark性能加速扩展不会安装Spark,只提供调优包安装和配置。配置Spark性能加速扩展后,还需修改配置文件,具体操作,请参见配置Spark性能加速扩展。
Spark性能加速扩展仅支持对Spark 3.3版本进行加速,如需支持其他版本,请您的商务经理开通。
具体操作,请参见安装扩展程序、卸载扩展程序。
默认安装的应用版本及性能提升
默认安装的应用版本及性能提升的说明如下表所示。
倚天实例
应用 | 默认安装应用版本 | 测试工具 | 主要指标 | 性能提升比例 |
Nginx | 1.20.1 | wrk | rps(requests per second) |
|
MySQL | 8.0.26 | sysbench | qps(queries per second) | 20%(纯读、纯写、混合读写) |
Redis | 6.0.2 | memtier-benchmark | rps(requests per second) | 25%(单pipeline小包场景) |
PostgreSQL | 13.10-1.0.1 | sysbench | qps(queries per second) | 20%(纯读、纯写、混合读写) |
Memcached | 1.5.22-2.1 | memtier-benchmark | rps(requests per second) | 10% ~ 20%(单pipeline小包场景) |
x264/x265 | ffmpeg 5.0.1+ x264 0.164.x+ x265 3.5+ | ffmpeg/x264/x265 | fps (frames per second) | x264编码:20%~30% x265编码:20%~30% |
Spark性能加速扩展 | 3.3 说明 不安装Spark,仅支持对Spark 3.3进行加速。 | TPC-DS | s(second) | 20%~60% |
AMD实例
应用 | 默认安装应用版本 | 测试工具 | 主要指标 | 性能提升比例 |
Nginx | 1.20.1 | wrk | rps(requests per second) | HTTP/HTTPS小包场景:10% |
MySQL | 8.0.26 | sysbench | qps(queries per second) | 5%(纯读、纯写、混合读写) |
Memcached | 1.5.22-2.1 | memtier-benchmark | rps(requests per second) | 7%(单pipeline小包场景) |
Intel实例
应用 | 默认安装应用版本 | 测试工具 | 主要指标 | 性能提升比例 |
MySQL | 8.0.26 | sysbench | qps(queries per second) | 7%(纯读、纯写、混合读写) |
推荐使用默认安装的应用版本,如果后续您自选应用版本,可能无法获取部分优化。优化范围说明如下:
应用本身性能收益(不使用默认安装的应用版本无法获取),包括应用二进制编译和应用配置的优化。
OS相关的性能收益(不使用默认安装的应用版本仍然可以获取),包括boot cmdline、内存配置、网络优化(绑核、XPS、RPS、RFS等)。
配置Spark性能加速扩展
在Spark的Master节点和所有Worker节点配置Spark性能加速扩展的详细步骤如下:
在Spark的Master节点和所有Worker节点安装Spark性能加速扩展。
在实例详情页,选择,单击。
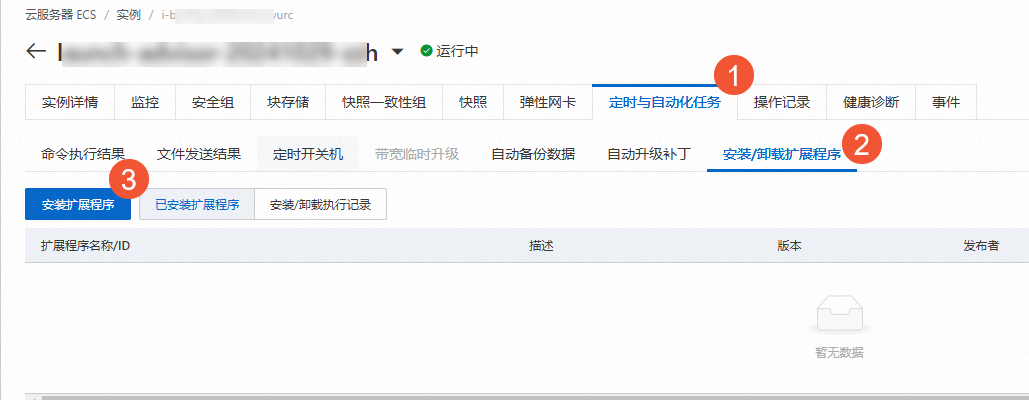
在安装扩展程序对话框中,公共扩展选择Spark性能加速扩展,配置如下参数,然后单击下一步,按照界面提示完成操作。
worker_number:指Spark集群中Worker节点的数量。
worker_type:指Worker节点的实例规格,当前仅支持ecs.g8y.8xlarge及以上规格和ecs.r8y.8xlarge及以上规格。

在Spark所有Worker节点配置ZSTD。
替换jar包。
sudo mv $SPARK_HOME/jars/zstd-*.jar $SPARK_HOME/jars/zstd-*.jar.bak sudo cp /opt/keentune/compress/zstd-*.jar $SPARK_HOME/jars/修改
/opt/keentune/spark.conf配置。如配置parquet文件写入过程的压缩方式,请修改以下参数:
spark.sql.parquet.compression.codec zstd spark.hadoop.parquet.compression.codec.zstd.level 1重要如果您的Parquet为1.13以下版本,建议您参考以下步骤升级到1.13及以上版本,以默认启用ZSTD的buffer pool。关于ZSTD JNI BufferPool的说明,请参见Support ZSTD JNI BufferPool。
wget https://repo1.maven.org/maven2/org/apache/parquet/parquet-column/1.13.1/parquet-column-1.13.1.jar wget https://repo1.maven.org/maven2/org/apache/parquet/parquet-common/1.13.1/parquet-common-1.13.1.jar wget https://repo1.maven.org/maven2/org/apache/parquet/parquet-encoding/1.13.1/parquet-encoding-1.13.1.jar wget https://repo1.maven.org/maven2/org/apache/parquet/parquet-format-structures/1.13.1/parquet-format-structures-1.13.1.jar wget https://repo1.maven.org/maven2/org/apache/parquet/parquet-hadoop/1.13.1/parquet-hadoop-1.13.1.jar wget https://repo1.maven.org/maven2/org/apache/parquet/parquet-jackson/1.13.1/parquet-jackson-1.13.1.jar sudo mv $SPARK_HOME/jars/parquet-*.jar $SPARK_HOME/jars/parquet-*.jar.bak sudo cp -rf parquet-*.jar $SPARK_HOME/jars如配置shuffle过程的数据压缩方式,请修改以下参数:
spark.io.compression.zstd.level 1 spark.io.compression.codec zstd
使用Spark存算分离时,需要配置OSS的Endpoint和AccessKey。
使用OSS存储时,必须在
/opt/keentune/spark.conf文件中配置s3a相关参数。spark.hadoop.fs.s3a.endpoint <OSS的Endpoint> spark.hadoop.fs.s3a.access.key <您的AccessKey ID> spark.hadoop.fs.s3a.secret.key <您的AccessKey Secret>在Spark的Master节点使用新的配置启动Spark集群。
您可以使用以下两种方式来启动Spark集群:
直接使用
/opt/keentune/spark.conf来重启Spark。# 任务提交方式一: spark-submit --properties-file=/opt/keentune/spark.conf # 任务提交方式二: spark-sql --properties-file=/opt/keentune/spark.conf参考优化后的配置修改您自己的spark.conf后重启Spark。
# 任务提交方式一: spark-submit --properties-file=${your_spark.conf} # 任务提交方式二: spark-sql --properties-file=${your_spark.conf}