ACK Edge集群可以纳管数据中心和边缘侧的GPU节点,统一管理多地域、多环境的异构算力。您可以在ACK Edge集群中接入阿里云Prometheus监控,使数据中心和边缘计算的GPU节点拥有与云上一致的可观测能力。
边缘节点可观测原理
ACK Edge集群支持通过专线和公网两种方式接入IaaS资源(例如IDC节点、第三方云厂商节点、IoT设备等)。在专线场景下,边缘节点通过专线与云端实现网络互通,确保Prometheus能够直接访问边缘节点,从而保证可观测能力的正常运行。在公网场景下,Prometheus通过Raven组件实现对边缘节点的可观测能力。具体实现步骤如下:

Prometheus是通过节点名称而非节点IP来采集指标,在域名解析时,CoreDNS配置了Hosts插件,将边缘节点名称解析至Raven Service。
Prometheus访问Raven Service时,最终从Service后端选择一个网关节点,与边缘侧的网络域进行通信。
网关节点上的Raven-agent会与IDC网关节点上的Raven-agent建立加密通道,支持三层和七层网络通信。
在IDC网络域的网关节点上,Raven-agent通过访问目标节点的GPU采集端口来获取监控数据。
监控边缘GPU节点
步骤一:开启阿里云Prometheus监控
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus 监控页面,按照页面提示完成相关组件的安装和监控大盘的检查。
控制台会自动安装组件、检查监控大盘。安装完成后,您可以单击各个页签查看相应监控数据。
步骤二:添加边缘GPU节点
添加边缘GPU节点具体操作,请参见添加GPU节点。
步骤三:在接入的GPU节点上部署应用以验证GPU相关指标正确性
本示例以运行TensorFlow Benchmark项目为例进行介绍,采用独占GPU调度能力,您还可以在边缘GPU节点上运行共享GPU的应用,请参见通过共享GPU调度实现多卡共享。
通过kubectl连接集群。
创建Job任务,并将其保存为tensorflow.yaml文件。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark-exclusive spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark-exclusive spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=5000000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申请1张GPU卡。 workingDir: /root restartPolicy: Never在集群中部署Job任务。
kubectl apply -f tensorflow.yaml
步骤四:查看GPU监控大盘
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus 监控页面,单击GPU 监控页签。
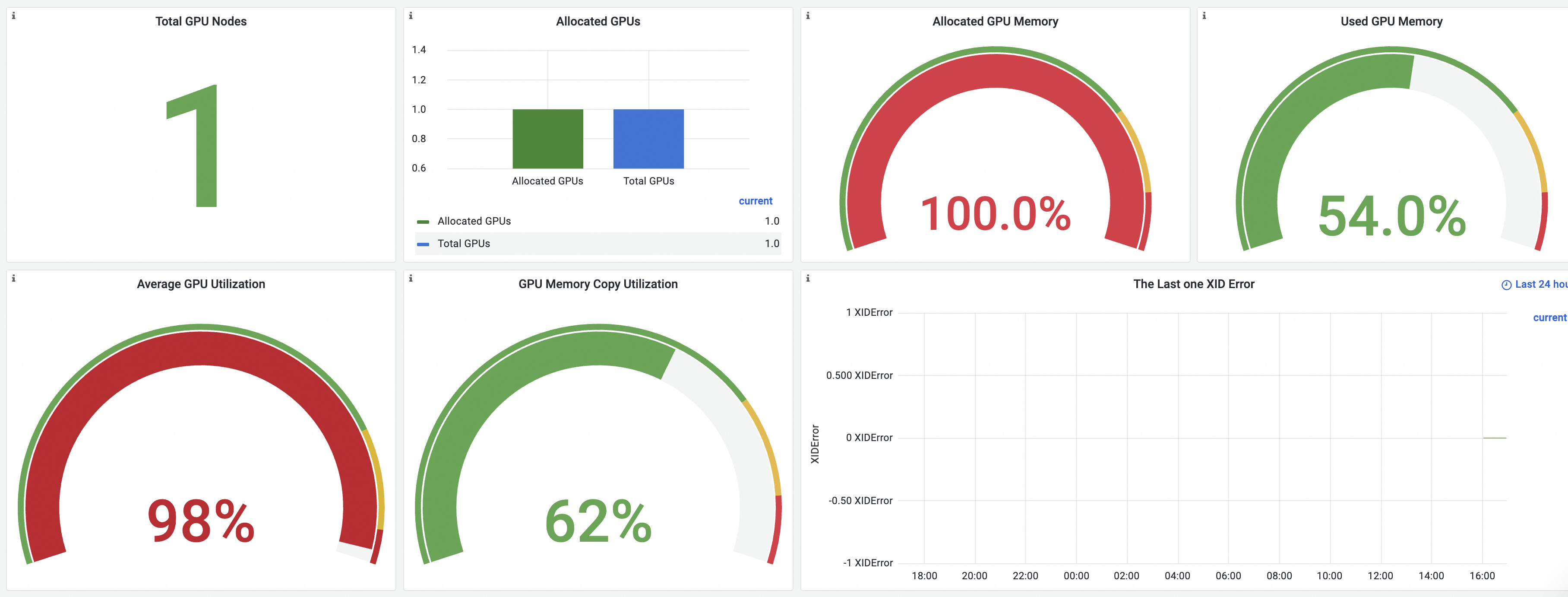
单击集群GPU监控-集群维度页签,可查看集群维度的大盘,关于大盘详细介绍,请参见查看集群维度GPU监控大盘。
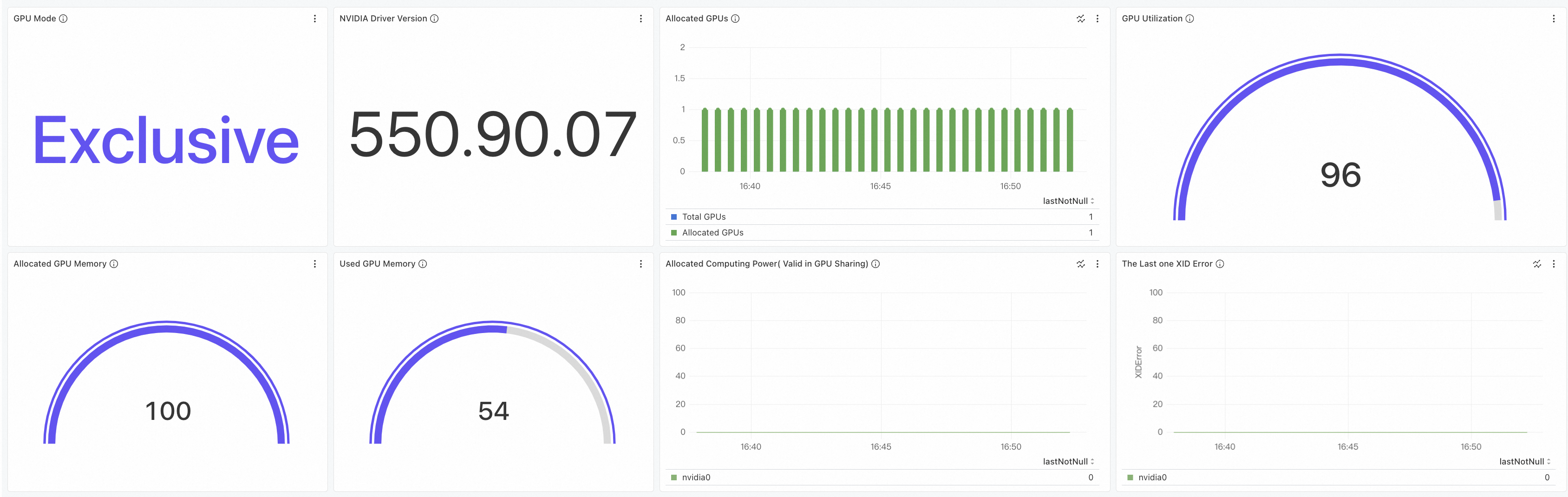
单击集群GPU监控-节点维度页签,可查看GPU节点维度的大盘。关于大盘详细介绍,请参见查看节点维度GPU监控大盘。
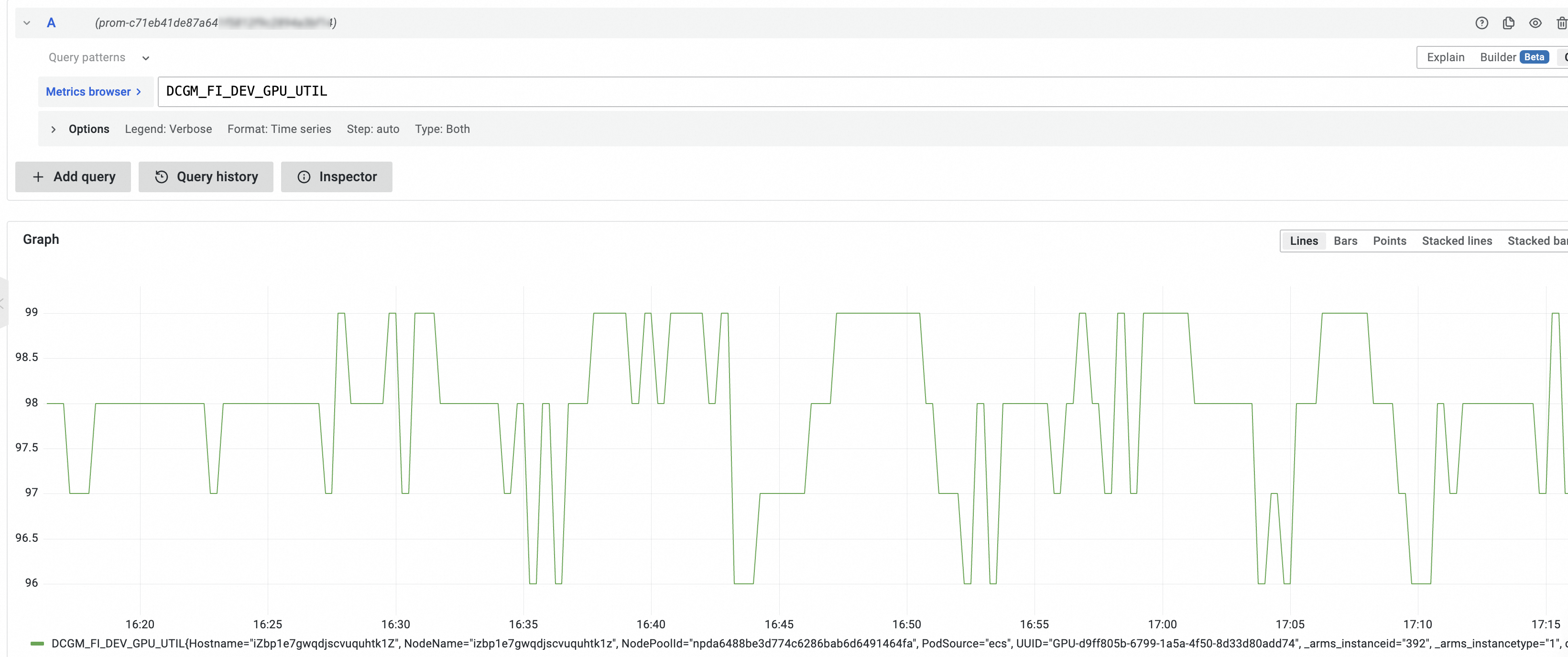
步骤五:查看边缘GPU节点监控指标
GPU监控使用的GPU Exporter在兼容开源DCGM Exporter提供的监控指标的基础上,根据某些业务场景,增加了自定义指标。关于DCGM Exporter的更多信息,请参见DCGM Exporter。
GPU监控中所涉及的GPU监控指标包括DCGM支持的指标和自定义指标,您可以通过以下操作查看GPU相关的监控指标。
GPU监控使用自定义指标会引起额外的费用。
为避免产生额外的费用,建议在启用此功能前,仔细阅读阿里云Prometheus的计费概述,了解自定义指标的收费策略。费用将根据您的集群规模和应用数量等因素产生变动。您可以通过资源消耗统计功能,监控和管理您的资源使用情况。
登录ARMS控制台。
在左侧导航栏选择。
在页面顶部下拉框选择目标实例。
在A区域设置查询指标,然后单击Run Query。