
对于需要文生图的业务场景,通过使用Stable Diffusion模型可以实现文生图功能。相比未使用DeepGPU加速的情况,借助DeepGPU可以加速Stable Diffusion模型的计算和推理性能。例如,文本生成分辨率为512x512图像的情况下,使用DeepGPU功能其加速性能可能提升约88%。本文为您介绍如何在GPU实例上部署SD-WebUI容器镜像以加速文生图。
加速效果示例
阿里云提供的SD-WebUI镜像中默认启用了DeepGPU加速功能,在GPU实例上部署SD-WebUI镜像可以加速文生图。
本示例仅展示一个简单的文生图加速效果,相比未使用DeepGPU加速场景(作为对比基线),使用DeepGPU加速功能,其加速性能提升88%左右。更多信息,请参见DeepGPU加速验证。
文本Prompt | 图像(分辨率) | 耗时(禁用DeepGPU功能) | 耗时(启用DeepGPU功能) | 加速性能提升率 |
| 多个苹果(512x512)
| 1.45 sec | 0.77 sec | 88% |

操作步骤
步骤一:获取SD-WebUI容器镜像信息
阿里云提供的SD-WebUI容器镜像通过DeepGPU工具进行加速,获取SD-WebUI容器镜像详细信息,以便您在GPU实例上部署该容器镜像时使用。例如,创建GPU实例时需要提前了解容器镜像适用的GPU实例类型,拉取容器镜像时需要提前获取镜像地址等信息。
登录容器镜像服务控制台。
在左侧导航栏,单击制品中心。
在仓库名称搜索框,搜索
sd-webui,并选择目标镜像egs/sd-webui。镜像详情如下所示:
镜像名称
组件信息
镜像地址
SD-WebUI
Deepgpu-sd:4.3.9-full
Python:3.10
PyTorch:2.1.2
CUDA:12.1.1
cuDNN:8.9.0.131
基础镜像:Ubuntu 22.04
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/sd-webui:4.3.9-full-pytorch2.1.2-ubuntu22.04
SD-WebUI
Deepgpu-sd:4.3.5-full
Python:3.10
PyTorch:2.1.2
CUDA:12.1.1
cuDNN:8.9.0.131
基础镜像:Ubuntu 22.04
egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/sd-webui:4.3.5-full-pytorch2.1.2-ubuntu22.04
步骤二:创建GPU实例
具体操作,请参见创建GPU实例。关键参数说明如下:
实例规格:建议选择内存30 GiB以上、GPU显存24 GB以上、vCPU无限制的实例规格(例如
ecs.gn7i-4x.8xlarge)。Stable Diffusion模型的推理过程需要耗费大量的计算资源,运行时占用大量内存,为了保证模型运行的稳定,建议您选择内存大的单卡GPU实例。SD-WebUI镜像仅支持在以下GPU实例规格族中配置:
gn7i、ebmgn7i、ebmgn7ix
gn7e、ebmgn7e、ebmgn7ex
gn8is、ebmgn8is
说明更多信息,请参见GPU计算型(gn/ebm/scc系列)。
镜像:选择公共镜像,建议选择Ubuntu 20.04及以上版本的镜像。
在GPU实例上部署SD-WebUI容器镜像,需要提前在该实例上安装Tesla驱动且驱动版本应为535或更高,建议您通过ECS控制台购买GPU实例时,同步选中安装GPU驱动。实例创建完成后,会自动安装Tesla驱动、CUDA、cuDNN库等,相比手动安装方式更快捷。
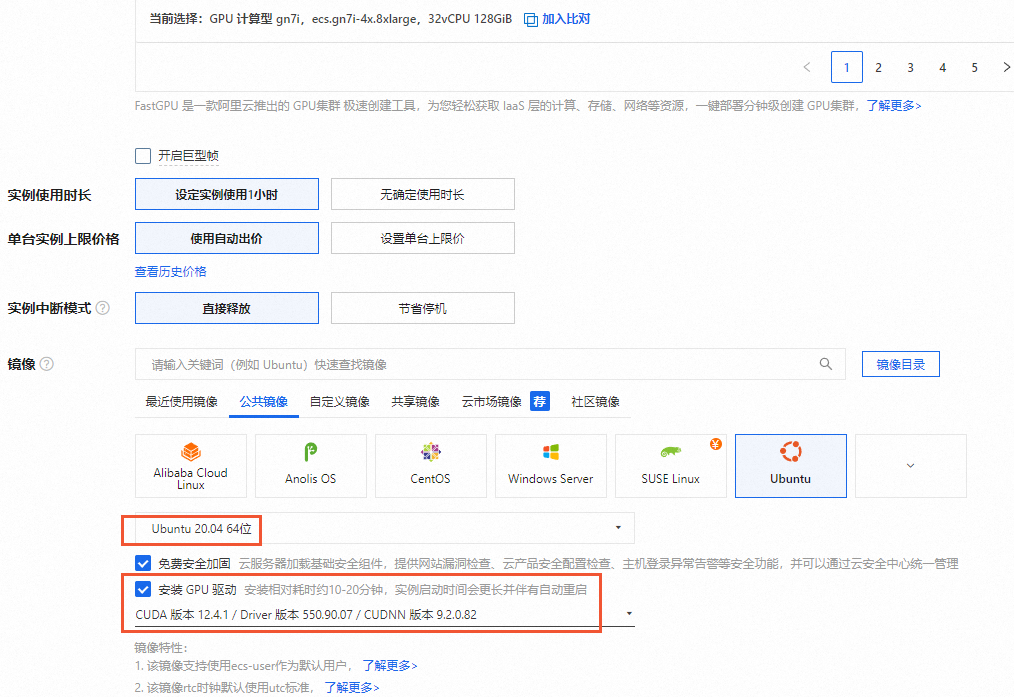
系统盘:Stable Diffusion的运行需要下载多个模型文件,会占用大量存储空间,为了保证模型顺利运行,建议系统盘设置为100 GiB。
公网IP:选中分配公网IPv4地址,带宽计费方式选择按使用流量,建议带宽峰值选择100Mbps,以加快模型下载速度。
步骤三:在GPU上配置SD-WebUI镜像
远程连接GPU实例。
具体操作,请参见使用Workbench工具以SSH协议登录Linux实例。
执行以下命令,安装Docker环境。
sudo apt-get update sudo apt-get -y install ca-certificates curl sudo install -m 0755 -d /etc/apt/keyrings sudo curl -fsSL http://mirrors.cloud.aliyuncs.com/docker-ce/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc sudo chmod a+r /etc/apt/keyrings/docker.asc echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] http://mirrors.cloud.aliyuncs.com/docker-ce/linux/ubuntu \ $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \ sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install -y docker-ce docker-ce-cli containerd.io执行以下命令,检查Docker是否安装成功。
docker -v如下图回显信息所示,表示Docker已安装成功。

执行以下命令,安装nvidia-container-toolkit。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update sudo apt-get install -y nvidia-container-toolkit设置Docker开机自启动并重启Docker服务。
sudo systemctl enable docker sudo systemctl restart docker执行以下命令,查看Docker是否已启动。
sudo systemctl status docker如下图回显所示,表示Docker已启动。
执行以下命令,拉取SD-WebUI镜像。
sudo docker pull <SD-WebUI镜像地址>请将代码中的
<SD-WebUI镜像地址>替换为您在操作步骤中获取的SD-WebUI镜像地址,示例如下:sudo docker pull egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/sd-webui:4.3.9-full-pytorch2.1.2-ubuntu22.04重要拉取镜像可能需要较长时间(20分钟甚至更久),请您耐心等待。
如果下载SD-WebUI镜像过程中,出现
no space left on device错误提示,说明您的磁盘空间不足,需要扩容云盘,然后再重新进行镜像下载。扩容云盘的更多信息,请参见云盘扩容指引。
执行以下命令,运行SD-WebUI容器。
h_mdir=/host/models/ # host models dir c_mdir=/workspace/stable-diffusion-webui/models # container dir sudo mkdir -p ${h_mdir}/Stable-diffusion cd ${h_mdir}/Stable-diffusion # 下载标准SD-1.5模型 sudo wget https://aiacc-inference-public-v2.oss-accelerate.aliyuncs.com/aiacc-inference-webui/models/v1-5-pruned-emaonly.safetensors # 启动容器 sudo docker run -c 32 --gpus all -it \ -v ${h_mdir}/Stable-diffusion/:${c_mdir}/Stable-diffusion/ \ -v ${h_mdir}/ControlNet/:${c_mdir}/ControlNet/ \ -v ${h_mdir}/Lora/:${c_mdir}/Lora/ \ -p 5001:5001 egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/sd-webui:4.3.9-full-pytorch2.1.2-ubuntu22.04SD-WebUI容器启动后,SD-WebUI服务自动启动。如果您需要修改服务启动命令或默认端口,请参照以下命令进行修改。例如,如需更改服务器监听端口为5002时,即将
--port 5001修改为--port 5002;如需更改模型检查点的目录为/example/path/ckpts时,即将--ckpt-dir ./ckpts改为/example/path/ckpts。cd /workspace/stable-diffusion-webui python -u ./launch.py --ckpt-dir ./ckpts --listen --port 5001 --enable-insecure-extension-access --disable-safe-unpickle --api --xformers --skip-install
DeepGPU加速验证
在安全组中,为您本地主机的IP(公网IP)开放入方向的访问SD-WebUI的端口。
本示例以开放入方向5001端口为例,具体操作,请参见添加安全组规则。

在浏览器中,输入
http://<GPU实例的公网IP>:5001访问SD-WebUI网站。在Web页面的文生图页签下,输入文本提示词,单击生成/Generate,等待生成图像。
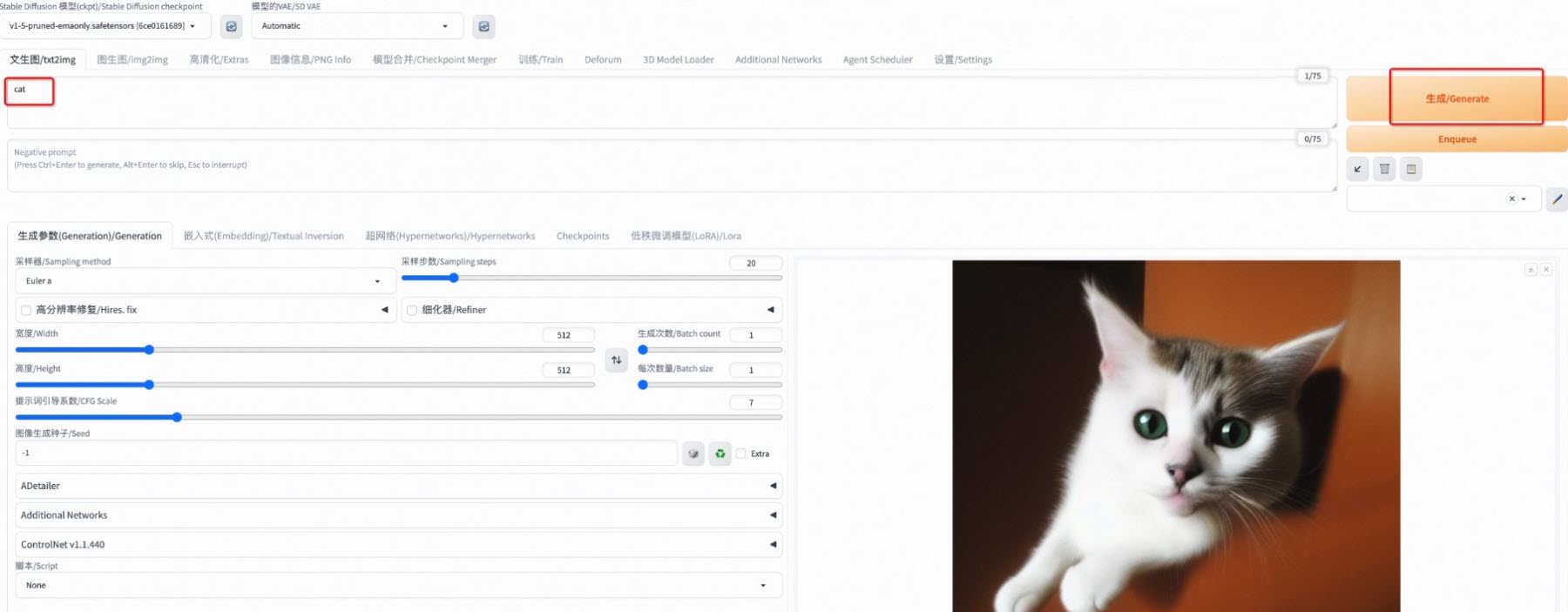
查看不同场景下的文生图时间,对比加速效果。
通过以下两种场景对比,相比禁用DeepGPU加速的场景(作为对比基线),在Stable Diffusion模型上启用DeepGPU加速功能,其加速性能提升约88%。
场景1:禁用DeepGPU加速功能
场景2:启用DeepGPU加速功能
操作说明:
按照本文操作后,再禁用DeepGPU加速功能。
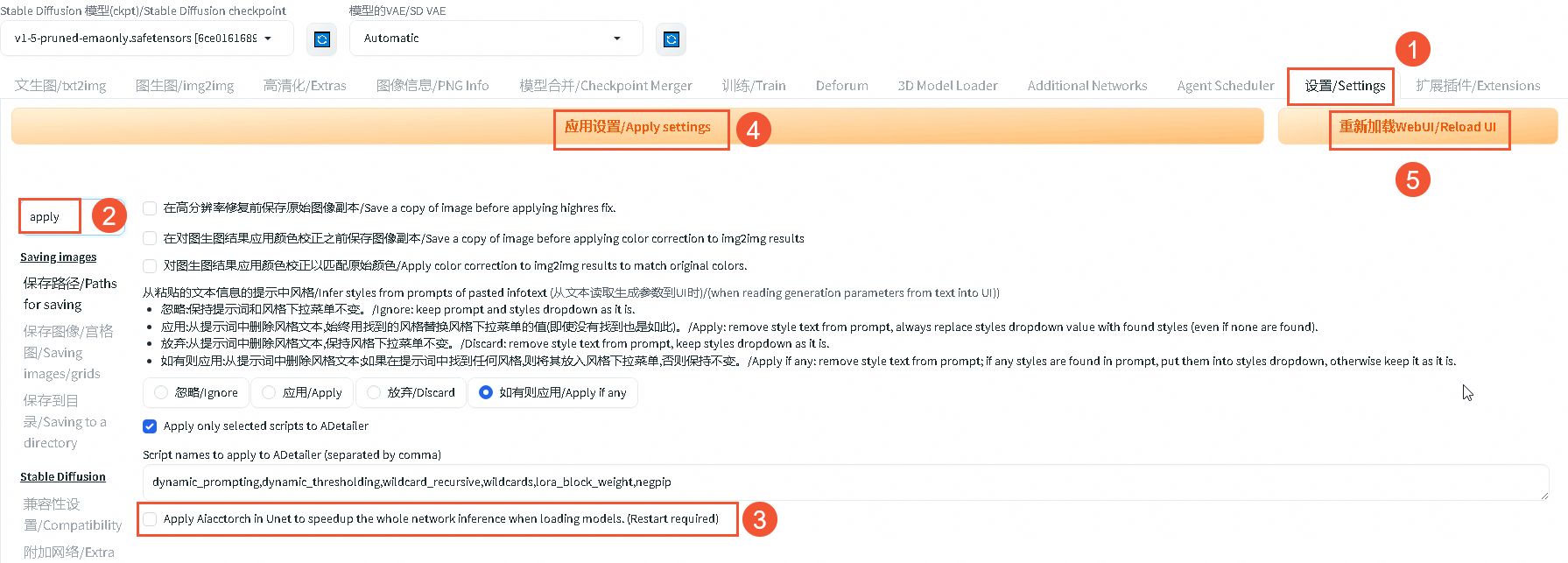
在SD-WebUI网站页面,单击设置/Settings。
在搜索框中输入
apply,并单击回车键。取消
Apply Aiacctorch in Unet to speedup the whole network inference when loading models.(Restart required)选项。单击应用设置/Apply settings。
单击重新加载WebUI/Reload UI。
重要应用设置后,请您重启WebUI服务器,因为仅通过重新加载WebUI并不能彻底清除原来的设置状态,后续可能会出现其他问题。
在Web页面的文生图页签下,进行文生图测试。
操作说明:
按照本文操作即可在模型上启用DeepGPU加速功能。
效果展示:禁用DeepGPU加速功能后,文生图所用时间为
1.43 sec。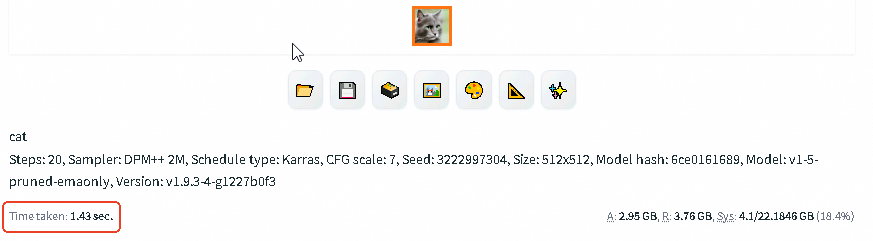
效果展示:启用DeepGPU加速功能后,文生图所用时间为
0.76 sec。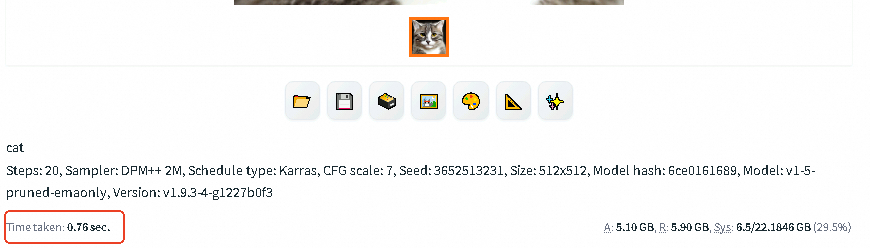
生产环境使用
如果想在实际生产环境中,借助DeepGPU加速文生图效率,建议您按照以下流程操作。
准备好自己的模型。
可以归档在本地,也可以归档在某个路径下方便下载。
按照本文操作步骤,部署SD-WebUI容器环境。
执行以下命令,在主机上设置用户模型的目录路径。
h_mdir=/host/models/ # 在主机上设置您自己模型的存放路径 sudo mkdir -p ${h_mdir}/Stable-diffusion # 在主机上创建一个名为Stable-diffusion的目录 sudo mkdir -p ${h_mdir}/ControlNet # 在主机上创建一个名为ControlNet的目录 sudo mkdir -p ${h_mdir}/Lora # 在主机上创建一个名为Lora的目录 cd ${h_mdir}/Stable-diffusion # 进入主机上的Stable-diffusion目录中下载您自己的模型至ECS主机。
模型存档在本地:将用户模型及模型组件上传到ECS主机的模型目录下(
/host/models/)。更多信息,请参见在本地Windows使用WinSCP向Linux实例传输文件。说明其中,用户自己的模型存在
/host/models/Stable-diffusion路径下,ControlNet组件存放在/host/models/ControlNet路径下,Lora组件存放在/host/models/Lora路径下。模型存档在某个路径:执行
sudo wget <用户模型下载路径>,下载您自己的模型。
执行以下命令,启动SD-WebUI容器,并将主机上的目录映射到SD-WebUI容器中的目录。
c_mdir=/workspace/stable-diffusion-webui/models # 设置SD-WebUI容器中的模型目录路径 sudo docker run -c 32 --gpus all -it \ -v ${h_mdir}/Stable-diffusion/:${c_mdir}/Stable-diffusion/ \ -v ${h_mdir}/ControlNet/:${c_mdir}/ControlNet/ \ -v ${h_mdir}/Lora/:${c_mdir}/Lora/ \ -p 5001:5001 egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/sd-webui:4.3.9-full-pytorch2.1.2-ubuntu22.04映射成功后,用户的模型就会自动在SD-WebUI容器中运行,访问SD-WebUI网站,您可以在Web页面看到文生图效果,您也可以根据实际需要在SD-WebUI页面配置不同的参数以满足实际场景需求。