
当升级GPU实例的操作系统(例如Alibaba Cloud Linux、RedHat、CentOS、Ubuntu等)内核时,可能会因为两个内核的kABI(Kernel Application Binary Interface)不一致,导致旧内核上构建的GPU(Tesla)驱动无法在新的内核上加载。内核升级后,请根据内核的kAPI(Kernel Application Programming Interface)是否存在变化,采取不同的方案解决该问题。
问题现象
升级GPU实例的操作系统内核时,出现GPU(Tesla)驱动无法在新的内核上加载,即无法在新的内核版本上插入旧内核的NVIDIA的KO,导致该驱动无法正常使用。报错信息如下:

问题原因
升级内核包后导致NVIDIA GPU(Tesla)驱动无法加载的可能原因如下:
升级前后两个内核的kABI不一致,导致旧内核上构建的NVIDIA GPU(Tesla)驱动无法在新内核上加载。
NVIDIA GPU(Tesla)驱动的默认KO(Kernel Object)安装目录不在
/lib/modules/(uname−r)/extra下,导致新的内核包安装时无法对其创建软链接。
解决方案
基于以上原因,根据内核的kAPI影响情况,采取不同的解决方案:
如果内核升级后,内核的kAPI不受影响,请通过DKMS自动构建NVIDIA GPU(Tesla)驱动。
如果内核升级后,内核的kAPI受到影响发生变化,无法通过DKMS自动构建NVIDIA GPU(Tesla)驱动,请重新适配NVIDIA GPU(Tesla)驱动。
通过DKMS自动构建NVIDIA GPU(Tesla)驱动
在NVIDIA GPU(Tesla)驱动上安装DKMS。
远程连接GPU实例。
本文以Alibaba Cloud Linux 3系统的gn7i实例为例,具体操作,请参见通过密码或密钥认证登录Linux实例。
在GPU实例上安装DKMS。
sudo yum install dkms手动为GPU安装NVIDIA GPU(Tesla)驱动。
具体操作,请参见在GPU计算型实例中手动安装Tesla驱动(Linux)。
安装过程中,请注意以下几点:
出现以下提示(即是否将内核模块源代码注册到DKMS)时,选择Yes。

选择Yes后NVIDIA GPU可能会报注册失败提示(如下图所示),您无需担心,直接单击OK即可。

根据实际需要选择是否安装NVIDIA的32位兼容性库。

执行以下命令,检测DKMS的当前状态。
sudo dkms status结果显示如下,表示DKMS已安装成功。

执行
ls命令,查看/usr/src/nvidia-${nvidia 驱动版本}目录下是否存放NVIDIA GPU(Tesla)驱动相关文件。本示例以
nvidia-${nvidia 驱动版本}为nvidia-470.141.03为例,请替换成您实际的驱动版本。 说明
说明NVIDIA GPU(Tesla)驱动默认将其相关代码或文件存放在
/usr/src/nvidia-${nvidia 驱动版本}目录下,以便DKMS在内核更新后自动重新编译和安装驱动程序的内核模块。
安装新内核触发DKMS自动构建NVIDIA GPU(Tesla)驱动。
本示例以新内核版本
5.10.134-15.al8为例,请您根据业务需要替换为实际的内核版本。重要建议先安装 kernel-devel包然后安装kernel/kernel-core包,否则,DKMS不会自动构建NVIDIA GPU(Tesla)驱动。因为kernel/kernel-core包触发DKMS,而DKMS构建NVIDIA GPU(Tesla)驱动需要kernel-devel包,此时需要手动触发DKMS构建NVIDIA GPU(Tesla)驱动。具体操作,请参见步骤3:手动触发DKMS构建Tesla驱动。
执行以下命令,安装新内核的kernel-devel包。
sudo rpm -ivh kernel-devel-5.10.134-15.al8.x86_64.rpm --force
安装kernel/kernel-core包。
本示例以安装kernel包为例。对于Alibaba Cloud Linux 3系统来说,需要安装kernel-core包,执行
sudo rpm -ivh kernel-core-5.10.134-15.al8.x86_64.rpm --force命令即可。sudo rpm -ivh kernel-5.10.134-15.al8.x86_64.rpm --force
执行以下命令,检查新内核下NVIDIA GPU(Tesla)驱动是否构建成功。
find /lib/modules/5.10.134-15.al8.x86_64/ -name *nvidia*
执行
sudo dkms status检查DKMS是否存在新的内核记录。
(条件必选)如果您先安装了kernel/kernel-core包,然后安装kernel-devel包,需手动触发DKMS构建NVIDIA GPU(Tesla)驱动。
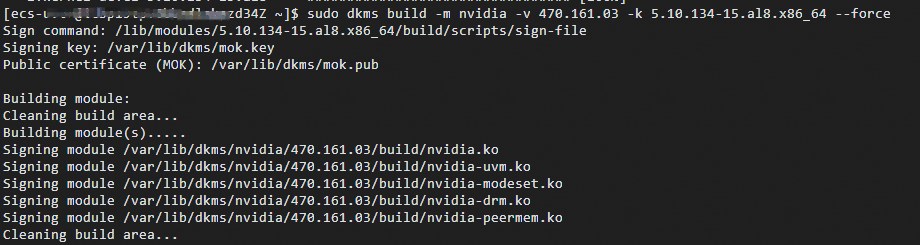
执行以下命令,构建NVIDIA GPU(Tesla)驱动。
sudo dkms build -m nvidia -v ${nvidia 驱动的版本} -k ${新的内核版本} --force主要参数说明如下:
${nvidia 驱动的版本}:请替换为NVIDIA GPU(Tesla)驱动的具体版本号,例如470.141.03。${新的内核版本}:请替换为新内核的具体版本号,例如5.10.134-15.al8.x86_64。
执行以下命令,安装已构建好的NVIDIA GPU(Tesla)驱动。
sudo dkms install -m nvidia -v ${nvidia 驱动版本} -k ${新的内核版本} --force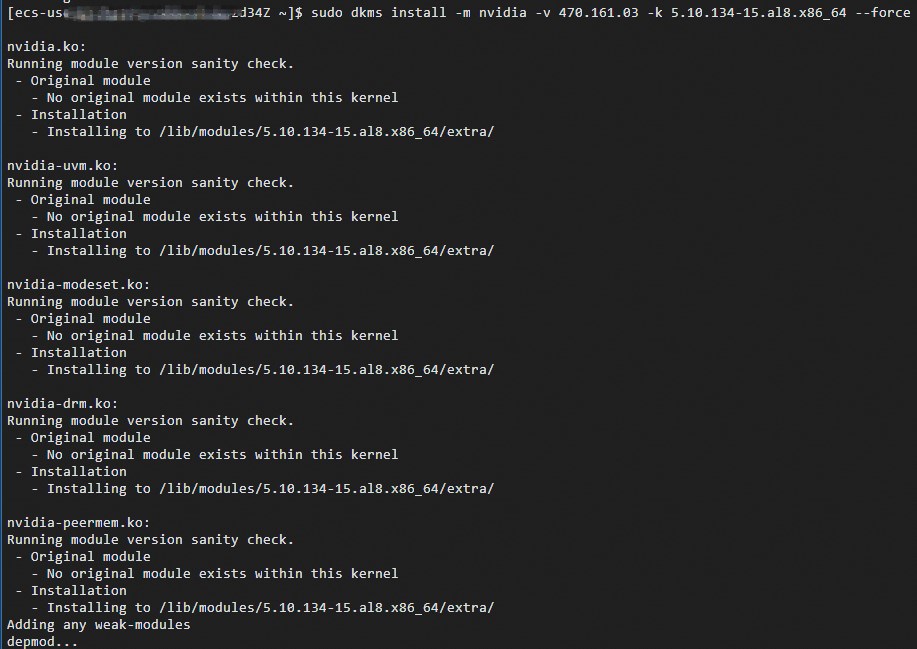
执行以下命令,检查新内核安装目录下NVIDIA GPU(Tesla)驱动是否已安装。
find /lib/modules/5.10.134-16.3.al8.x86_64/ -name *nvidia*
执行
sudo dkms status检查DKMS是否存在新的内核记录。
重新适配NVIDIA GPU(Tesla)驱动
如果内核升级后导致内核的kAPI受到影响发生变化,通过DKMS无法自动构建和安装NVIDIA GPU(Tesla)驱动,您需要重新适配NVIDIA GPU(Tesla)驱动。具体操作,请参见:在GPU计算型实例中手动安装Tesla驱动(Linux)。