
对于Ubuntu操作系统GPU计算型实例(即ebmgn7、ebmgn7e、ebmgn7ex或sccgn7ex),如果您采用安装包方式安装了nvidia-fabricmanager服务,则apt-daily服务可能会自动更新已安装的软件包,使得该软件版本与Tesla驱动版本不一致,产生版本兼容性问题,导致nvidia-fabricmanager服务启动失败,最终影响GPU无法正常使用,本文介绍这种情况的解决方案。
问题现象
采用安装包方式安装nvidia-fabricmanager服务后,查看该服务状态时,出现如下报错信息,该情况会导致GPU无法正常使用。

问题原因
在Ubuntu系统的GPU实例上,通过安装包方式安装了nvidia-fabricmanager服务后,由于apt-daily服务会自动更新nvidia-fabricmanager软件,使得该软件版本与Tesla驱动版本不一致,基于版本兼容性问题,导致nvidia-fabricmanager服务启动失败,最终影响GPU无法正常使用。
解决方案
nvidia-fabricmanager软件版本必须与Tesla驱动版本一致,才能确保GPU的正常运行。为了预防或解决nvidia-fabricmanager软件版本与Tesla驱动版本不一致带来的GPU无法使用问题,请参考以下操作。
查看nvidia-fabricmanager软件和Tesla驱动版本信息。
执行以下命令,查看nvidia-fabricmanager软件版本信息。
sudo dpkg --list |grep nvidia-fabricmanager本示例以nvidia-fabricmanager软件版本为
550.90.07为例,其中,nvidia-fabricmanager-550为软件包名称,550.90.07为软件版本。
执行以下命令,查看Tesla驱动版本信息。
nvidia-smi本示例以Tesla驱动版本为
550.90.07为例。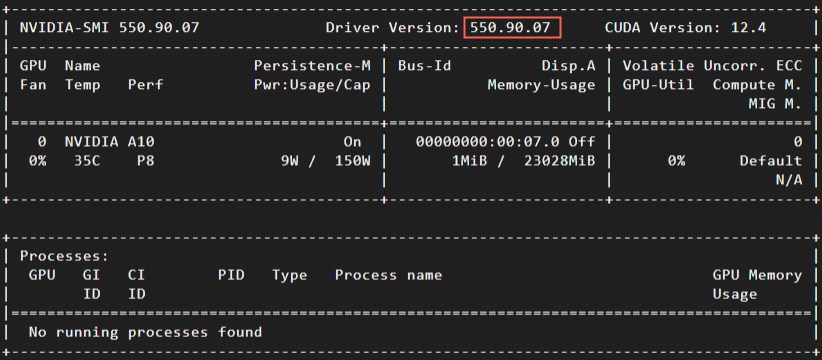
确认当前nvidia-fabricmanager版本与Tesla驱动版本是否一致。
如果两版本一致,继续执行下一步。
如果两版本不一致,请选择以下任一方案:
升级Tesla驱动确保与nvidia-fabricmanager版本保持一致。具体操作,请参见升级NVIDIA Tesla驱动。
卸载当前nvidia-fabricmanager服务并重新安装后,继续执行下一步。
说明如需了解如何卸载nvidia-fabricmanager服务,请参见步骤1:卸载nvidia-fabricmanager服务。
执行以下命令,禁止nvidia-fabricmanager软件被自动更新或升级。
本示例以
nvidia-fabricmanager-550软件包名称为例,请替换成您实际的nvidia-fabricmanager软件包名称。sudo apt-mark hold nvidia-fabricmanager-550显示结果如下,表示nvidia-fabricmanager软件已禁止更新。

执行以下命令,确认
nvidia-fabricmanager软件更新已被锁定(hold)。sudo apt-mark showhold例如结果显示
cloud-init和nvidia-fabricmanager-550信息,表示相应的软件更新已被锁定。