
在Linux系统GPU实例中,可能会因为GPU实例所安装的CUDA版本与PyTorch版本不兼容,导致使用PyTorch时出现报错现象,本文介绍这种情况的解决方案。
问题现象
在Linux系统(例如Alibaba Cloud Linux 3操作系统)GPU实例中使用PyTorch时,出现如下报错信息:
>>> import torch
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/torch/__init__.py", line 235, in <module>
from torch._C import * # noqa: F403
ImportError: /usr/local/lib/python3.8/dist-packages/torch/lib/../../nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkAddData_12_1, version libnvJitLink.so.12问题原因
可能是GPU实例所安装的CUDA版本与PyTorch版本不兼容导致上述报错,关于CUDA版本与PyTorch版本的匹配详情,请参见Previous PyTorch Versions。
通过sudo pip3 install torch安装的PyTorch版本为2.1.2,要求的CUDA版本为12.1。而购买GPU实例自动安装的CUDA版本为12.0,与PyTorch要求的CUDA版本不匹配。
解决方案
如果购买GPU实例时,在镜像区域的公共镜像页签下选中了安装GPU驱动选项,则您可以按以下三种方案升级CUDA版本至CUDA 12.1。
停止现有GPU实例。
具体操作,请参见停止实例。
在实例列表中,找到已停止的GPU实例,在对应的操作列,选择。
修改用户数据,然后单击确定。
将
DRIVER_VERSION、CUDA_VERSION、CUDNN_VERSION参数修改为如下版本:... DRIVER_VERSION="535.154.05" CUDA_VERSION="12.1.1" CUDNN_VERSION="8.9.7.29" ...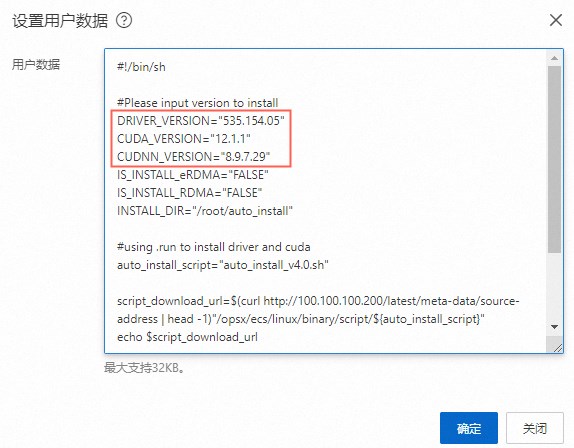
更换GPU实例的操作系统。
具体操作,请参见更换操作系统(系统盘)。
待GPU实例启动成功后,系统会重新安装新版本的NVIDIA Tesla驱动、CUDA以及cuDNN。